Prometheus 基本高可用架构
本文最后更新于:2025年2月22日 下午
「转载」Prometheus 基本高可用架构
Prometheus 作为一个 Metrics 系统,需要保证自身的稳定性和可用性。Prometheus 的单体架构存在单点故障,并且随着监控规模的扩展,大量的数据读写也会使单体架构的响应变慢,不便扩展,所以需要引入 prometheus 的高可用集群。本文将介绍 prometheus 常见的三种 HA 架构:简单 HA、简单 HA + 远端存储、简单 HA + 远端存储 + 联邦。
简单 HA 架构
简单 HA 使用多个配置相同的 prometheus 去采集相同的 target, 并使用一个负载均衡如 Nginx 路由到任意一台 prometheus,即使其中一台服务挂掉,仍然能保证 prometheus 的监控服务可用。Prometheus alertmanager 是自带的告警模块,将集群的多个 prometheus 的告警对接到一个告警模块。简单 HA 如下图所示。
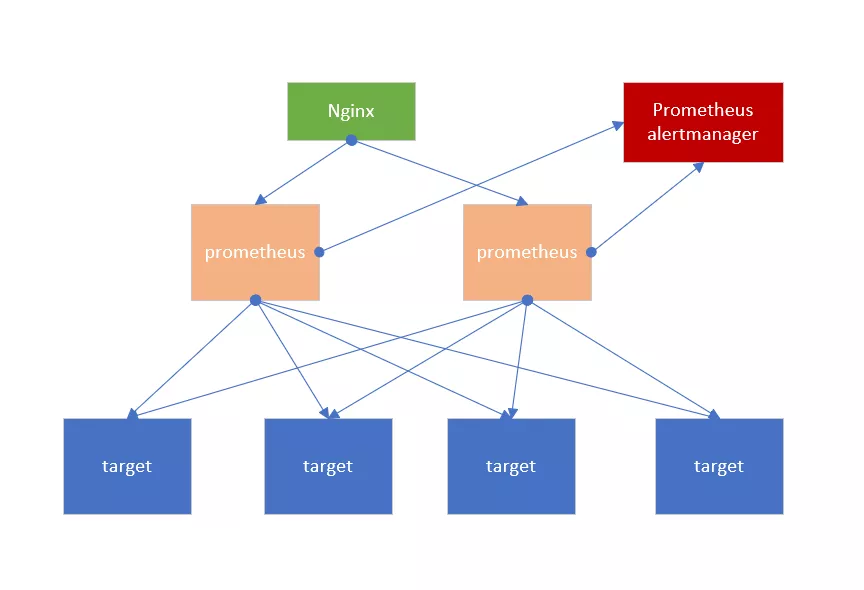
这种架构就是比较简单的 HA,只是部署多个一模一样的实例去干同样的事,保证整个监控服务不会出现单点故障。但是,即便多个一模一样配置的 prometheus,也会出现数据不一致的情况。简单 HA 中各个 prometheus 的采集周期是一样的,但开始采集的时间并不是固定的,并且加上不稳定的网络延时,所以就会造成各个 prometheus 之间的数据并不是完全一致的。在稳定性方面也存在着问题,这种架构下,如果数据丢失的话是无法进行恢复的,如果 prometheus 实例经常迁移,或动态扩展,这个架构就没那么灵活。另外因为没有额外的远端存储,这种架构不足以支持 prometheus 存储大量或长时间的数据。这种方案适合监控规模不大且不需要存储长期或大量数据的场景。这种架构在一致性、存储容灾、迁移、动态扩展、远端存储方面都存在问题。
简单 HA + 远端存储
此种架构只是在简单 HA 的基础上加了个远程存储,通过使用 prometheus 自带的远程读写接口(prometheus remote read 和 remote write)去对接诸如 InfluxDB、OpenTSDB 等第三方存储,将数据写入远程的存储库中。Prometheus 存储以及查询数据在合并本地数据后进行远程数据的处理,就解决了简单 HA 架构中存在的数据一致性、持久化、迁移性、扩展性问题。简单 HA + 远端存储如下图所示。
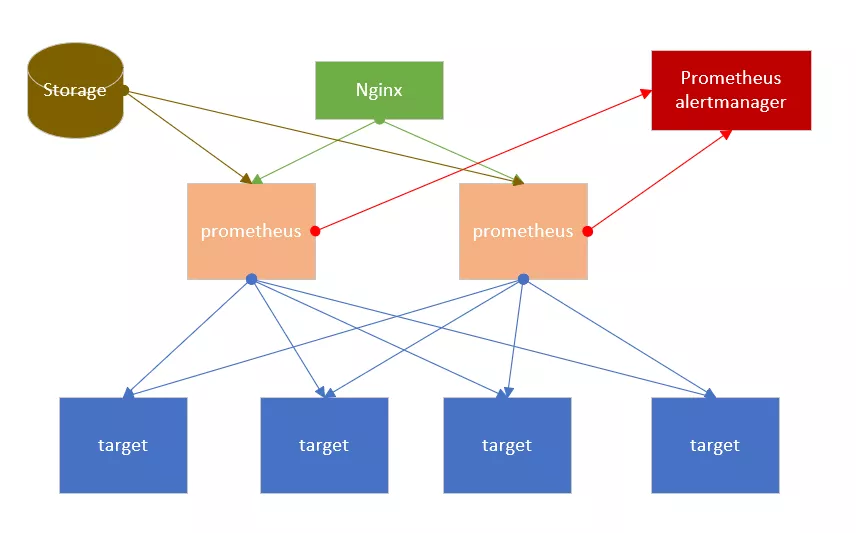
但是,在开启远程存储后所需的内存可能会飙升 3-4 倍,prometheus 的 Commiter 认为 25%-35% 的内存占用是比较正常的,有人建议将最大 Shard 数量减少到 50 来降低内存占有率。这是因为远程存储往往需要先把 WAL 中的数据写完,一般来说 WAL 会保存约 2 小时的数据,所以会启动很多进程,所以需要限制。
这种架构,能够满足一些中小型企业的监控需求,短期(如 15 天)内的监控数据可以从本地取,长期的数据从远程存储中获取,并且因为有了远程存储,prometheus 迁移或者宕机重启可以很快进行数据恢复。
但是这个架构也还存在着一些问题,当监控规模较大时,prometheus 有限的服务器节点在采集能力上有明显的瓶颈,海量的数据对于远端存储来说也有着巨大的挑战。prometheus 远程存储比本地存储会占用更多的内存和 CPU,此时可以通过减少 label 和采集间隔以降低资源占用,或者增大资源限制。
简单 HA + 远端存储 + 联邦集群
这个架构也是在上一个方案的基础上扩展来的,主要解决的就是单个 prometheus 的采集瓶颈问题。联邦集群可以将监控采集任务以分治法的形式划分给不同的 prometheus 实例分别处理,以实现功能分区,这种架构利于水平扩展。简单 HA + 远端存储 + 联邦集群如下图所示。
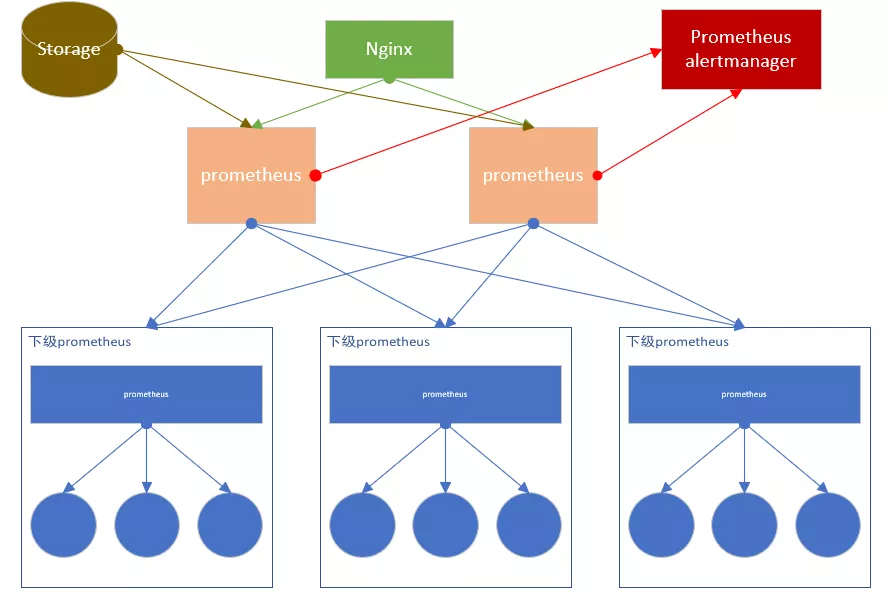
这种联邦集群的架构方式大大提高了单个 prometheus 的采集能力和存储能力如图所示,最下面一级的 prometheus 可以分别在分别在不同的区域、机房进行数据采集,上一级的 prometheus 作为联邦节点,负责定时从下级 prometheus 节点获取数据并汇总。多个联邦节点大大保证了可用性。需要注意的是部分敏感报警尽量不要通过 Global 节点(上层节点,只负责收集和存储聚合数据)触发,毕竟从 shard 节点到 Global 节点传输链路的稳定性会影响到数据到达的效率,进而导致报警实效性降低。例如,服务 UP DOWN 状态、API 请求异常这类报警我们都放在 shard 节点进行。
这种方案,主要在解决单个 prometheus 采集瓶颈的问题,降低了单个 prometheus 的采集压力,同时通过联邦节点汇聚主要数据,降低本地存储的存储压力,在避免单点故障方面也有不错的优势。
但是这种架构也有一定的问题,主要的问题有:
-
每个集群部都部署一套独立的 prometheus,在通过 grafana 等可视化工具查看每个集群的数据,缺乏统一的全局视图。
-
配置比较复杂,需要对下层的 prometheus,进行任务拆分,将不同的采集点,分别分配到下层每个 prometheus 上。
-
需要比较完整的数据备份方案和历史数据存储方案以保证监控存储的高可用性。
-
缺少对历史数据的降准、采样能力。
-
面对监控数据海量洪峰,也要进行一系列优化。
-
数据一致性和准确性可能降低。下级节点会按照设定的间隔时间抓取目标,而上级节点要抓取下级节点的数据,这会导致到达主节点的数据出现延迟,从而导致数据倾斜和告警延迟。
-
在使用过程中,根据经验,联邦对采集点大约会有 5% 的额外内存开销,实际使用过程中需要评估资源的使用量。
使用 prometheus 联邦集群可以实现,prometheus 监控 prometheus,但需要遵循以下两点原则:
-
采用网络模式,在同一个数据中心每个 prometheus 都可以监控其他的 prometheus。
-
采用上下级模式,上一级的 prometheus 监控数据中心级别的 prometheus。
除此之外,为了避免下一级的 prometheus 的单点故障,可以部署多个 prometheus 节点,但是效率上会差很多,并且每个监控对象会被重复采集,数据也会被重复保存。
在联邦集群的主备架构中,通常采用 keepalived 的方式实现主备切换。Master 节点获取各个采集层的 prometheus 数据,Slave 节点不去查询数据;如果 Master 节点宕机了,keepalived 会将 VIP 自动切换到 Slave 节点,同时去除 Master 节点中采集的 Target 相关设置,并且启动 Slave 节点采集 Target 的相关设置。
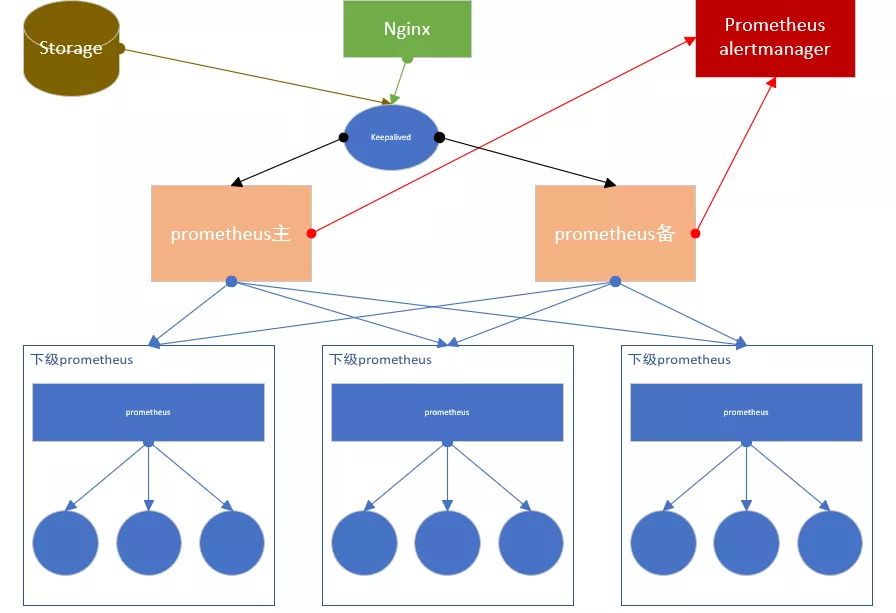
简单 HA + 远端存储 + 联邦集群这种方案,适合中大型企业,尤其是单数据中心,大数据量的采集任务或者是多数据中心的场景。相比之下可能采用 thanos 的方案更好一点。
📓 参考文档:
监控集群优化
从部署方式入手的优化就是根据是应用场景的不同来选取最合适的架构方案,而从内部入手进行优化可以保证我们的系统内部也能做到最佳。
-
尽早去除高纬度的数据。在以 prometheus 为代表的的指标监控系统中,有一个很重要的概念 —— Cardinality 基数,他代表 label 的可能取值。正常来说,单实例的 Cardinality 基数值应该在 10 个左右。高纬度的数据也就是有很多个标签或标签值的指标,每新增一个 Label 值就等于在存储时创建了一个时间序列,如果 Label 值过多,即高纬度的数据,一方面会占据大量的存储空间,另一方面也会在聚合的时候消耗过量的资源。所以像 Email 地址,用户地址,IP 地址等都不适合作为 Label. 使用一些警告规则可以帮助你找出那些坏的高纬度指标,然后在 Scrape 配置里丢掉纬度过高的指标:
1
2# 统计每个指标的时间序列数,超出 10000 的报警
count by (__name__)({__name__=~".+"}) > 10000 -
对于被监控的系统,一定要关注你最需要的 20 个以内的指标,最好不要对所有指标都要进行采集,可以对你采集点的系统进行指标梳理,整理出对你最有帮助的核心指标。降低 prometheus 的采集指标的数据,是对 prometheus 集群部署时进行的最佳优化。
-
运用合理且正确的 PromQL。对不同的指标类型,使用相关函数的顺序要正确使用。
原文作者
👉️URL: https://mp.weixin.qq.com/s/hjx3GOtDfwVmAOz4qTeSFw

作者 / 赵一晗
