「译文」如何使用 PromQL join 来更有效地查询大规模的 Prometheus 指标
本文最后更新于:2025年2月22日 下午
📝Description:
我们帮助一个强大的用户使用 PromQL 连接消除了对 18,000 条单独规则的需求。下面是方法。
我们最近听说一个客户,一个 Prometheus 的高级用户,正在为其指标处理 18,000 条单独的规则,因为其设置涉及为每个生成的指标创建一个单独的规则组。肯定有一个更好、更有效的方法来处理这种规模的指标?事实上,我们确实想出了一个解决方案,这篇博文将告诉你,你也可能从中受益。
我们要做的是
该组织正在为每个生成的指标创建一个单独的规则组。
比如说。
1 | |
上面的记录规则的原因是,客户想把 reference_label 添加到指标的汇总版本中。参考标签对应的是每个系列上已经存在的两个预先存在的标签。目前的问题是如何在不改变基础系列的情况下,用所需的相关参考标签创建新的聚合系列?
在想出一个替代方案时,我们考虑到了以下几点。
Info metrics
普罗米修斯中的信息度量是一种不对测量进行编码的度量,而是用来对高基数的标签值进行编码。一个信息度量的例子是 node_uname_info。
1 | |
上述指标是由 node exporter 暴露的,是一个测量值总是设置为 1 的仪表。尽管这个指标本身没有什么用处,但它与其他指标一起使用会很有用。例如,如果你想通过操作系统的 release 来确定 CPU 闲置时间,你可以使用查询:
1 | |
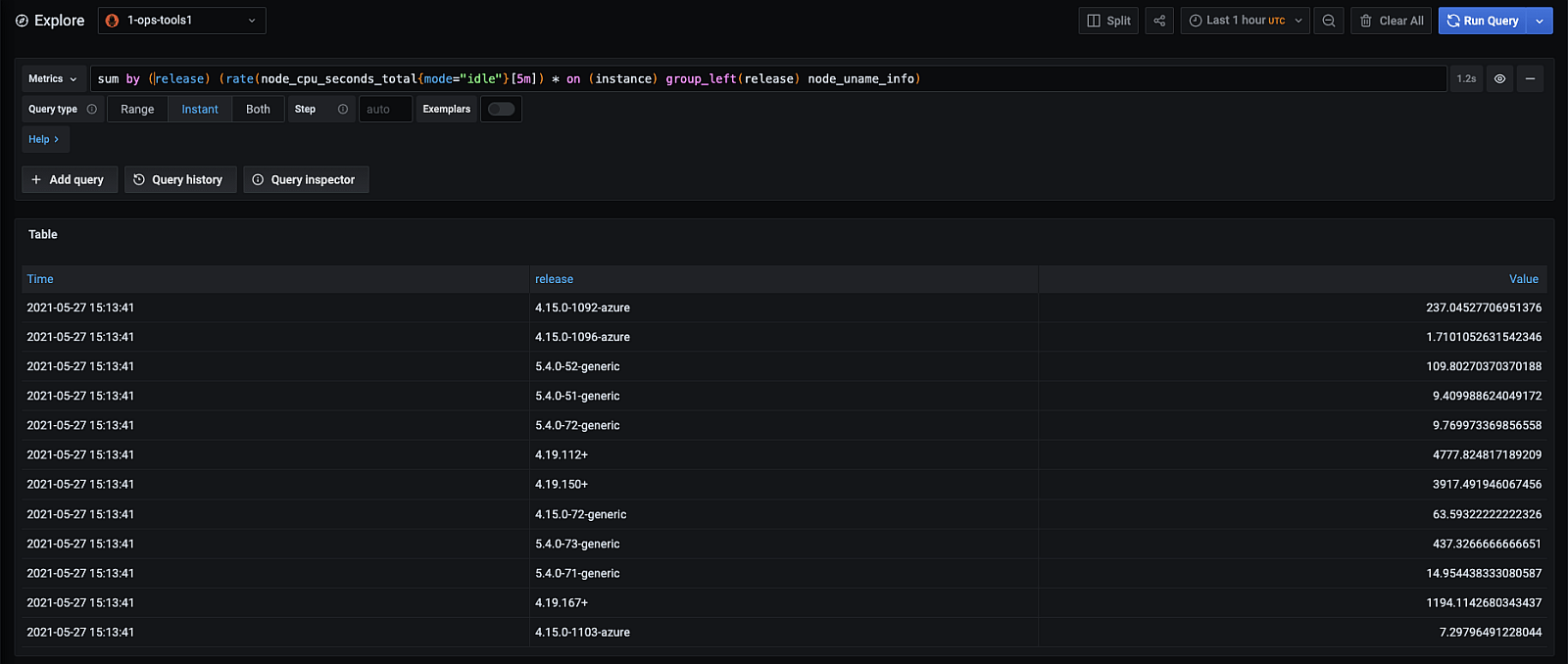
你可能有的下一个问题是,你如何能够轻松地创建一个具有正确标签值的信息指标,并迅速将其刮入 Prometheus。你总是可以用你想要的指标来创建一个应用程序,但还有一个更简单的方法。你可以利用 textfile_collector 的优势。
Textfile exporter
Prometheus node exporter 和 Grafana agent 支持 textfile collector。这允许代理解析和收集包含 Prometheus 论述格式 度量的文本文件。这个功能对于快速生成包含对 PromQL 查询有用的元数据的静态度量是很重要的。
利用上述功能,你可以创建包含独特标签集的信息指标,这些标签可以在 PromQL join 查询中与其他指标一起使用。你所需要做的就是创建一个包含你所需要的信息指标的文件,并将它们暴露给 Prometheus。你可以手动或脚本来做这件事。
关于一些可用于生成包含旨在由 textfile collector 收集的指标的文件的脚本示例,请参见 Prometheus 社区脚本库。
Joins in PromQL
PromQL 支持将两个度量连接在一起的能力。你可以从一个度量中附加一个标签集,并在查询时将其附加到另一个度量中。这在 Prometheus 规则评估中很有用,因为它可以让你通过附加另一个信息度量的标签为一个系列生成一个新的度量。
关于连接运算符的更多信息,请参阅 Prometheus 查询运算符的文档,并查看这些博客文章。
把所有的东西集中起来
你可以重新利用生成 18000 个规则组的工具,转而生成一个包含 sli_info 指标的普罗米修斯指标文件。这个指标将包含 seal reference 和 sealID、检查标识(checkID)以及任何其他它适当映射到的标签。
接下来,使用 Grafana agent 内置的 textfile collector 收集生成的度量,并将其写入 Cortex。
为每个指标运行一条规则,使用 PromQL join 将适当的参考标签注入生成的系列中。
例如,基于上述规则组:
1 | |
你将创建以下信息指标文件:
1 | |
这个文件将被 Grafana Agent 收集。然后在 Cortex 中可以使用以下规则组:
1 | |
这将对具有这些标签名称和相关映射的每个指标起作用。
瞧!你得到了与现有规则组相同的结果,而没有 18000 个单独的规则。你得到了与现有规则组相同的结果,而没有 18,000 条单独的规则。
