「读书笔记」《大规模分布式存储系统:原理解析与架构实战》:五
本文最后更新于:2025年2月22日 下午
5 分布式键值系统
可以看成是分布式表格模型的一种特例。
哈希分布算法。
5.1 Amazon Dynamo
| 问题 | 采取的技术 |
|---|---|
| 数据分布 | 改进的一致性哈希(虚拟节点) |
| 复制协议 | 复制写协议(Replicated-write Protocol,NWR 参数可调) |
| 数据冲突处理 | 向量时钟 |
| 临时故障处理 | 数据回传机制(Hinted handoff) |
| 永久故障后的恢复 | Merkle 哈希树 |
| 成员资格及错误检测 | 基于 Gossip 的成员资格和错误检测协议 |
5.1.1 数据分布
一致性哈希算法思想:给系统中每个节点分配一个随机 token,这些 token 构成一个哈希环。执行数据存放操作时,先计算主键的哈希值,然后存放到顺时针方向第一个大于或等于该哈希值的 token 所在的节点。
一致性哈希的优点:节点加入、删除时只会影响到在哈希环中相邻的节点,而对其他节点没有影响。
Dynamo 使用了改进的一致性哈希算法:每个物理节点根据其性能的差异分配多个 token,每个 token 对应一个「虚拟节点」。每个虚拟节点的处理能力基本相当,并随机分布在哈希空间中。
由于种子节点的存在,新节点加入比较简单。新节点首先与种子节点交换集群信息,从而对集群有了认识。DHT(Distributed Hash Table,一致性哈希表)环中的其他节点也会定期和种子节点交换集群信息,从而发现新节点的加入。
5.1.2 一致性与复制
复制:数据回传。
Dynamo 亮点技术:NWR,N 表示复制的备份数,R 指成功读操作的最少节点数,W 指成功写操作的最少节点数。 只要满足 W + R > N,就可以保证当存在不超过一台机器故障的时候,至少能够读到一份有效的数据。
如果应用重视读效率,可以设置 W = N,R=1;如果应用需要在读写之间权衡,一般可以设置 N=3,W=2,R=2。
NWR 看似完美,实则不然。在 Dynamo 这样的 P2P 集群中,由于每个节点存储的集群信息有所不同,可能出现同一个记录被多个节点同时更新的情况,无法保证多个节点之间的更新顺序。为此 Dynamo 引入向量时钟(Vector Clock)的技术手段尝试解决冲突。
5.1.3 容错
Dynamo 将异常分为 2 种类型:
- 临时性的异常:如机器假死
- 永久性的异常:如硬盘报修或机器报废等
容错机制:
- 数据回传
- Merkle 树同步
- 读取修复
5.1.4 负载均衡
取决于如何给每台机器分配虚拟节点号,即 token。
分配节点的方法:
- 随机分配:缺点是可控性差。
- 数据范围分配 + 随机分配
5.1.5 读写流程

读取过程中,如果数据不一致,默认策略是根据修改时间戳选择最新的数据,当然用户也可以自定义冲突处理方法。读取过程中如果发现某些副本上数据版本太旧,Dynamo 内部会异步发起一次读取修复操作,使用冲突解决后的结果修正错误的副本。

5.1.6 单机实现
Dynamo 的存储节点包含 3 个组件:
- 请求协调
- 成员和故障检测
- 存储引擎
Dynamo 设计支持可拔插 的存储引擎,如 Berkerly DB,MySQL InnoDB 等。
5.1.7 讨论
Dynamo 采用无中心节点的 P2P 设计,增加了系统的可扩展性。
Dynamo 只保证最终一致性,多客户端并发操作的时候很难预测操作结果,也很难预测不一致的时间窗口。
总体来看,Dynamo 在 Amazon 的使用场景有限,后续的类似系统会采用其他设计思路以提供更好地一致性。
5.2 淘宝 Tair
Tair 是淘宝开发的一个分布式 K/V 存储引擎。Tair 分为持久化和非持久化两种使用方式:
- 非持久化可以看成是个分布式缓存
- 持久化的 Tair 将数据存放于磁盘中。
Tair 可配置数据的备份数目。
5.2.1 系统架构
组成:
- 1 个中心控制节点 - config server:负责管理所有 Data Server,维护其状态信息。一主一备。
- 若干服务节点 - data server:对外各种数据服务,并以心跳的形式将自身情况汇报给 Config Server。
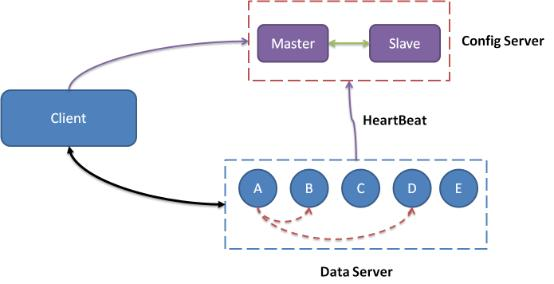
5.2.2. 关键问题
数据分布
哈希后,分布到 Q 个桶中。Q 要远大于集群的物理机器数,如 Q = 10240
容错
数据迁移
config server
客户端缓存路由表。
Data Server
Data Server 具备抽象的存储引擎层,可以很方便地添加新存储引擎。Data Server 还有一个插件容器,可以动态加载、卸载插件。
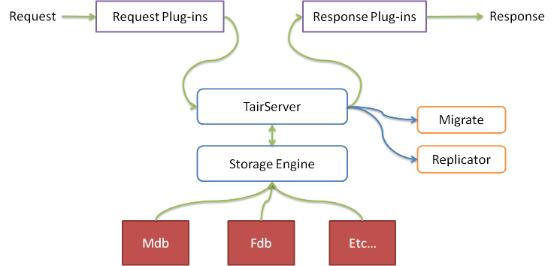
默认包含两个存储引擎:
- Mdb
- Fdb
5.2.3 讨论
Tair 中引入了中心节点 Config Server。这样很容易处理数据的一致性,不再需要向量时钟、数据回传、Merkle 数、冲突处理等复杂的 P2P 技术。另外,中心节点的负载很低。
Tair 持久化不尽如人意。如,Tair 持久化存储通过异步复制技术提高可靠性,可能会丢数据。
