Grafana 系列 - 统一展示 - 8-ElasticSearch 日志快速搜索仪表板
本文最后更新于:2025年2月22日 下午
系列文章
概述
我们是基于这篇文章: Grafana 系列文章(十二):如何使用 Loki 创建一个用于搜索日志的 Grafana 仪表板 , 创建一个类似的,但是基于 ElasticSearch 的日志快速搜索仪表板.
最终完整效果如下:
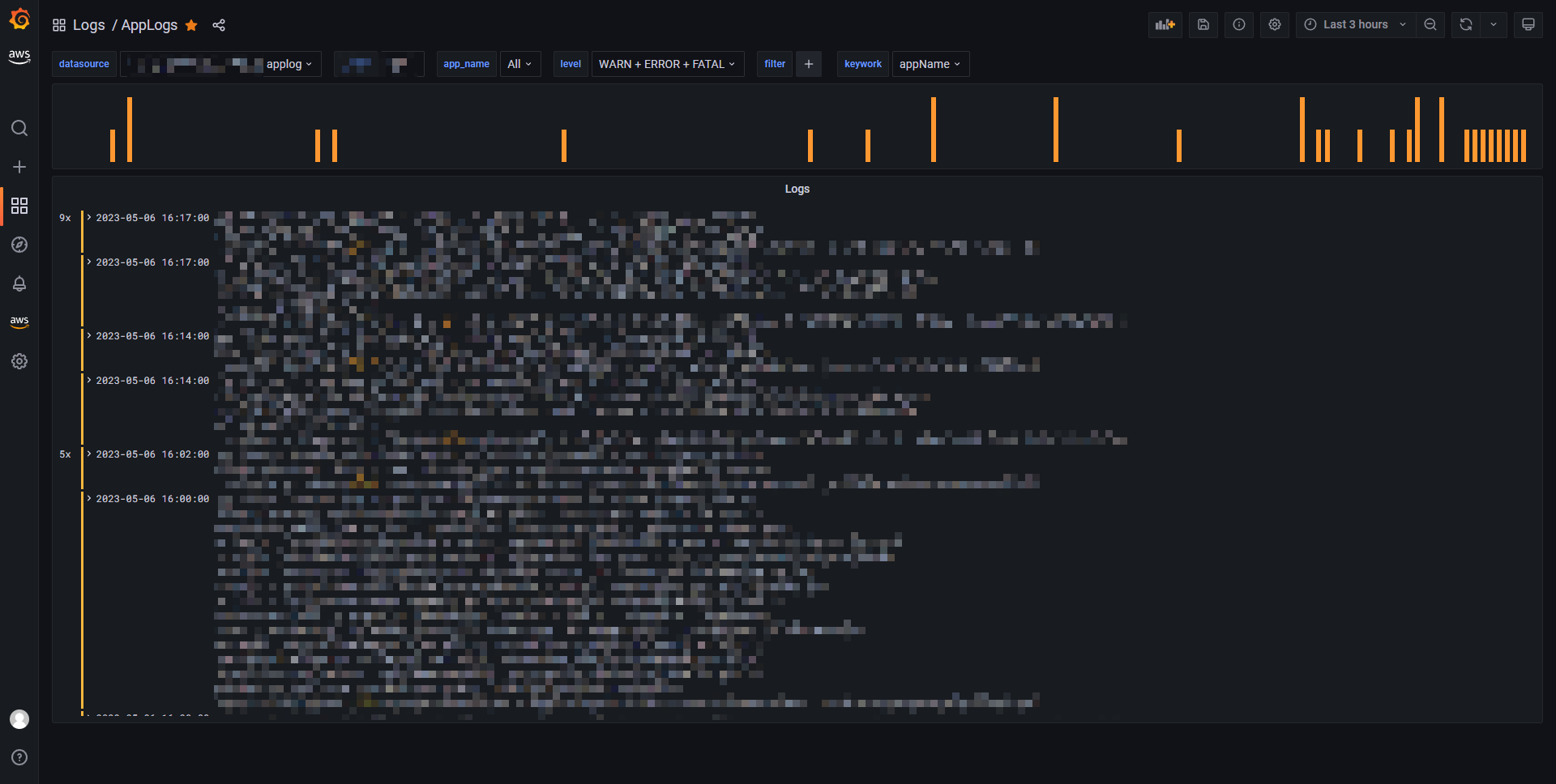
📝Notes:
其实我基于 ElasticSearch 做了 2 个仪表板
- 用于检索 Applog 的
- 用于检索 accesslog 的
在下面的讲解中会综合 2 个仪表板来进行说明.
这次不会讲述详细细节,只选择部分关键点进行说明.
知识储备
创建 Query
使用自定义的 JSON 字符串编写查询,field 在 Elasticsearch 索引映射中被映射为一个 keyword。
如果查询是 multi-field 的 text 和 keyword 类型,使用 "field": "fieldname.keyword"(有时是 fieldname.raw)来指定你查询中的关键字字段。
Query
| Query | Description |
|---|---|
{"find": "fields", "type": "keyword"} |
返回一个索引类型为 keyword 的字段名列表。 |
{"find": "terms", "field": "hostname.keyword", "size": 1000} |
使用 terms 聚合返回一个 keyword 的值列表。查询将使用当前仪表板的时间范围作为时间范围查询。 |
{"find": "terms", "field": "hostname", "query": '<Lucene query>'} |
使用 terms 聚合和指定的 Lucene 查询过滤器,返回一个 keyword field 的值列表。查询将使用当前仪表板的时间范围作为查询的时间范围。 |
terms 的查询默认有 500 个结果的限制。要设置一个自定义的限制,需要在你的查询中设置 size 属性。
Variable 语法
面板标题和 metric 查询可以使用多种不同的语法来引用变量:
$varname, 这种语法很容易阅读,但它不允许你在词的中间使用变量。例如:apps.frontend.$server.requests.count${var_name}, 当你想在表达式的中间插值一个变量时,请使用这种语法。${var_name:<format>}这种格式让你对 Grafana 如何插值有更多控制。[[varname]]不建议使用。废弃的旧语法,将在未来的版本中删除。
高级变量格式选项
变量插值的格式取决于数据源,但在有些情况下,你可能想改变默认的格式。
例如,MySql 数据源的默认格式是以逗号分隔的方式连接多个值,并加引号,如:'server01', 'server02'. 在某些情况下,你可能希望有一个不带引号的逗号分隔的字符串,如:server01,server02。你可以用下面列出的高级变量格式化选项来实现这一目的。
通用语法
语法: ${var_name:option}
可以在 Grafana Play 网站上测试格式化选项。
如果指定了任何无效的格式化选项,那么 glob 就是默认 / 回退选项。
CSV
将具有多个值的变量形成一个逗号分隔的字符串。
1 | |
分布式 - OpenTSDB
以 OpenTSDB 的自定义格式对具有多个值的变量进行格式化。
1 | |
双引号
将单值和多值变量形成一个逗号分隔的字符串,在单个值中用 \" 转义 ",并将每个值用 "" 引号括起来。
1 | |
Glob - Graphite
将具有多个值的变量组成一个 glob(用于 Graphite 查询)。
1 | |
JSON
将具有多个值的变量形成一个逗号分隔的字符串。
1 | |
Lucene - Elasticsearch
以 Lucene 格式对 Elasticsearch 的多值变量进行格式化。
1 | |
URL 编码 (Percentencode)
对单值和多值变量进行格式化,以便在 URL 参数中使用。
1 | |
Pipe
将具有多个值的变量形成一个管道分隔的字符串。
1 | |
Raw
关闭数据源特定的格式化,如 SQL 查询中的单引号。
1 | |
Regex
将有多个值的变量形成一个 regex 字符串。
1 | |
单引号
将单值和多值变量形成一个逗号分隔的字符串,在单个值中用 \' 转义',并将每个值用' 引号括起来。
1 | |
Sqlstring
将单值和多值变量组成一个逗号分隔的字符串,每个值中的' 用'' 转义,每个值用' 引号括起来。
1 | |
Text
将单值和多值变量转换成其文本表示法。对于一个单变量,它将只返回文本表示法。对于多值变量,它将返回与 + 相结合的文本表示法。
1 | |
查询参数
将单值和多值变量编入其查询参数表示法。例如:var-foo=value1&var-foo=value2
1 | |
配置变量选择选项
Selection Options 是一个你可以用来管理变量选项选择的功能。所有的选择选项都是可选的,它们在默认情况下是关闭的。
Multi-value Variables
内插一个选择了多个值的变量是很棘手的,因为如何将多个值格式化为一个在使用该变量的给定环境中有效的字符串并不直接。Grafana 试图通过允许每个数据源插件告知模板插值引擎对多个值使用什么格式来解决这个问题。
📝Notes:
变量上的 Custom all value 选项必须为空,以便 Grafana 将所有值格式化为一个字符串。如果它留空,那么 Grafana 就会把查询中的所有值连接起来(加在一起)。类似于
value1,value2,value3。如果使用了一个自定义的所有值,那么该值将是类似于*或all的东西。
带有 Prometheus 或 InfluxDB 数据源的多值变量
InfluxDB 和 Prometheus 使用 regex 表达式,所以 host1, host2, host3 变量会被插值为 {host1,host2,host3}。每个值都会被 regex 转义。
使用 Elastic 数据源的多值变量
Elasticsearch 使用 lucene 查询语法,所以同样的变量会被格式化为 ("host1" OR "host2" OR "host3")。在这种情况下,每一个值都必须被转义,以便该值只包含 lucene 控制词和引号。
Include All 选项
Grafana 在变量下拉列表中添加了一个 All 选项。如果用户选择了这个选项,那么所有的变量选项都被选中。
自定义 all 的值
这个选项只有在选择了 Include All option 时才可见。
在 Custom all value 字段中可以输入 regex、globs 或 lucene 语法来定义 All 选项的值。
默认情况下,All 值包括组合表达式中的所有选项。这可能会变得非常长,而且会产生性能问题。有时,指定一个自定义的所有值可能会更好,比如通配符。
为了在 Custom all value 选项中拥有自定义的 regex、globs 或 lucene 语法,它永远不会被转义,所以你将不得不考虑什么是你的数据源的有效值。
ElasticSearch Template Variables
选择一种 Variable 语法
如上文所述,Elasticsearch 数据源支持在查询字段中使用多种变量语法.
当启用 Multi-value 或 Include all value 选项时,Grafana 会将标签从纯文本转换为与 Lucene 兼容的条件。即隐式转换 $varname 为 ${varname:lucene}
实战
1. 弄清楚有哪些索引字段
首先,最重要的,就是弄清楚该索引有哪些索引字段 (fields), 以及有哪些 keywords, 选择部分字段和 keywords 作为 varibles. 可以直接通过 Kibana 界面进行查询和尝试.
如本次选择的有:
app_namelevelrequest_path(🐾 通过多次在 Kibana 上使用发现,查询时应该使用request_path.keyword而不是request_path)request_methodstatus_code
2. 创建 Variables
app_name
设置如下:
- Name:
app_name - Type: Query
- Data source: ES
- Query:
{"find": "terms", "field": "current_app_name"}, 另外,如果嵌套使用,可以类似这样{"find": "terms", "field": "pod_name", "query": "app_name:$app_name"}
request_path
设置如下:
- Name:
request_path - Type: Query
- Data source: ES
- Query:
{"find": "terms", "field": "request_path.keyword", "query": "app_name:$app_name"} - Multi-value: ✔️
- Include All option: ✔️
- Custom all value:
*
🐾 注意,这里使用了 Custom all value, 最终 Query All 的表达式就会变成: request_path.keyword:* 而不是 request_path.keyword:(<path1> OR <path2> ...)
request_method
request_method 常用的就这么几个:
- GET
- POST
- DELETE
- HEAD
- PUT
- PATCH
- OPTIONS
所以可以将其设置为 Custom variable, 设置如下:
- Name:
request_method - Type: Custom
- Values separated by comma:
GET,POST,DELETE,HEAD, PUT,PATCH,OPTIONS - Multi-value: ✔️
- Include All option: ✔️
- Custom all value:
*
level
日志级别可以直接使用 Custom 类型变量。如下:
- Name:
level - Type:
Custom - Values separated by comma:
INFO, WARN, ERROR,FATAL - Multi-value: ✔️
- Include All option: ✔️
如果只关注错误日志,那么 level 变量的默认值可以设置为同时勾选: ERROR 和 FATAL
status_code
这里会将 status_code variable 用于 Lucene 的范围语法 [](包括开头和结尾的 2 个数字), 所以有用到 Custom all value 以及 Variable 语法配置.
- Name:
status_code - Type:
Custom - Values separated by comma:
200 TO 299, 300 TO 399, 400 TO 499, 500 TO 599 - Include All option: ✔️
- Custom all value:
200 TO 599(📝Note: 即包括所有的 http 状态码,从 200 到 599)
后续要在 Query 中使用,用法如下:
1 | |
直接使用 ${status_code:raw}, 这样传入就会变成:
1 | |
按期望完成对 ES 的查询.
filter
最后,还添加一个 Ad hoc filters variable, 方便用户进行更多自定义的过滤筛选.
- Name: filter
- Type:
Ad hoc filters - Data source:
${datasource}
后续会在该 Dashboard 的所有 Query 中自动使用。一个典型使用场景如下:
对于 request_path, 需要过滤监控 / 健康检查等请求 (包含 info health metric 等关键词), 那么可以将该 filter 保存为默认的变量值.

3. Panel
Dashboard 只有 2 个面板组成:
- 上图: Time series, 显示日志柱状图,并着色,
INFO日志为绿色,WARN日志为黄色,ERROR和FATAL日志为红色. - 下日志
Time series panel
如下图:

可以通过如下 Query 实现:
1 | |
$level AND INFO 这种写法是一个 workaround, 为的是在 level 变量改变时,Time series panel 随之改变.
另外一个需要注意的点是,Metric 是 Count(日志条数) 而不是 Logs (具体日志).
还有,需要配置 Override -> Color, 如下:
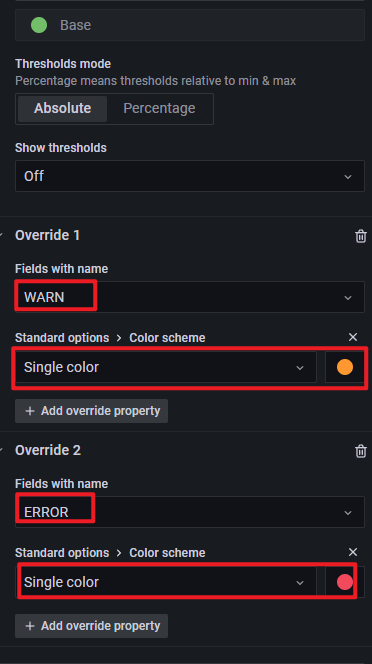
最后,如果柱子太密,可以通过调整如 3 Colors Time series panel 图中的 Interval 来调整时间间隔,本例调整为 1m
Logs panel
在 Logs panel 中,也可以根据实际情况做一系列调整.
如下图,可以对日志展示方式做调整:
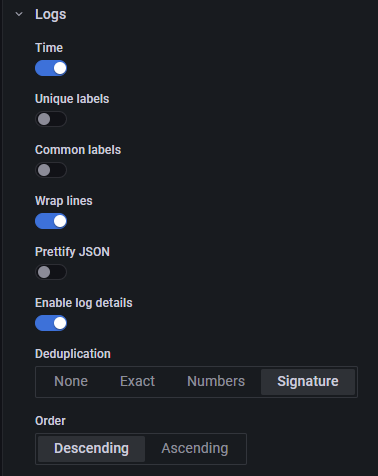
- Time: 是否加时间戳
- Unique labels: 是否每条日志加 label
- Common labels: 是否对 logs panel 左上角对所有日志加 common labels
- Wrap lines
- Pretify JSON: JSON 美化
- Enable log details: 启用查看日志详细信息
- Deduplication: 日志去重,去重方式有:
- None: 不去重
- Exact: 精确去重
- Numbers: 不同数字记为同一类的去重方式
- Signature: 根据计算得出的 Signature 去重
- Order: 排序.
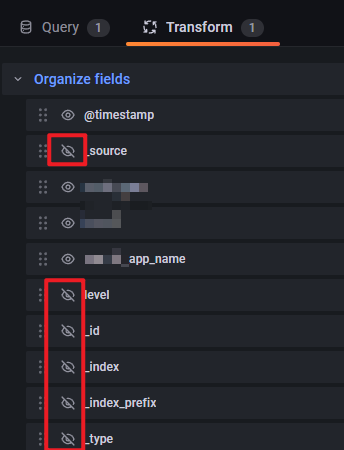
另外,考虑到 ES 日志的 log details 会有很多我们不关注的 fields, 如: _source _id 等,可以通过 Transform 进行转换调整。具体如下图:
总结
这篇文章算是该系列文章的一个重点了。包含了非常多的实用细节.
如:
- ES Query
- Variable 语法
- Variable raw 语法
- Lucene - Elasticsearch 语法
- …
- Multi-value Variables
- Include All 选项
- 自定义 all 的值
Ad hoc filtersVariable- ES Metric Type
- Count
- Logs
- …
- 调整 Query 时间间隔
- Logs panel 设置
- Panel Transform
希望对你有所帮助.
