「译文」开源日志监控:Grafana Loki 简要指南
本文最后更新于:2024年7月25日 下午
👉️URL: https://grafana.com/blog/2023/12/11/open-source-log-monitoring-the-concise-guide-to-grafana-loki/
✍️Author: Ed Welch
📝Description:
在 Grafana Loki 庆祝成立五周年之际,我们来看看这个项目走过了怎样的历程,以及使其成为最受欢迎的开源日志解决方案之一的基本功能。
五年前的今天,Grafana Loki 在 KubeconNA 2018 的舞台上被介绍给全世界,当时 David Kaltschmidt(现任 Grafana Labs 工程部高级总监)在全场爆满的观众面前点击按钮,将 Loki repo public 现场公开。当时,Loki 只是一个原型: 我们将 Grafana 作为用户界面、Cortex 内核和 Prometheus 标签组合在一起,以了解是否需要一种新的开源工具来管理日志。
那么,另一种日志聚合工具是否有市场呢?当然,毫无疑问。多年来,这种工具越来越受欢迎。如今,活跃的 Loki 集群已超过 100,000 个;该项目在 GitHub 上的星已超过 20,000 颗星;我们还看到 Loki 在各种使用案例中广泛应用–无论是在家庭实验室的 Raspberry Pis 上运行,还是在拥有数万 CPU 内核的大规模多租户集群上运行。最重要的是,我们非常感谢由近 900 名贡献者组成的社区,是他们帮助我们将这个原型发展成为一个令人印象深刻、功能强大的软件。

为了庆祝 Loki 成立五周年,我想总结一下我们的日志聚合工具这些年来是如何发展的。我知道,在这些年里,我肯定也在不断学习和发展。我的 Loki 之旅始于 Loki 发布几周后。事实上,我是在更新自制气象站时看到 grafana.com 上的 “我们正在招聘” 横幅后申请加入 Grafana 实验室的。
2020 年,我写了一篇名为标签简明指南的博客,我觉得这可能是我为 Loki 创建的最有用的内容–短小精悍、重点突出、易于分享和消费。在接下来的几周里,我将围绕几个 Loki 主题,以类似的风格撰写一系列文章(免责声明:顺序和具体内容可能会有变化,它们尚未撰写😏):
- 标签: 2020 年以来的变化
- 日志排序和摄取旧数据
- 查询性能: 如何以 300+GB/s 的速度进行查询的速成课程
- 缓存 101(也许还有 201)
- 保留和删除
- 大小
自 2018 年以来发生了很多变化。Loki 的内部结构经过了多次迭代,在某些情况下甚至被替换了数次;然而,从概念上讲,它并没有发生什么变化。因此,作为本系列的开篇,让我们来谈谈 Loki 的概念、它的设计初衷(以及它的非设计初衷),以及它最终将成为什么。
欢迎阅读 Loki 简明指南。
Loki 的设计目的
设计理念非常简单:利用 Prometheus 标签的分类系统、Grafana 提供的单一窗格以及 Cortex 的云原生分布式系统设计,构建一个高度可扩展且非常适合 Kubernetes 的日志系统。
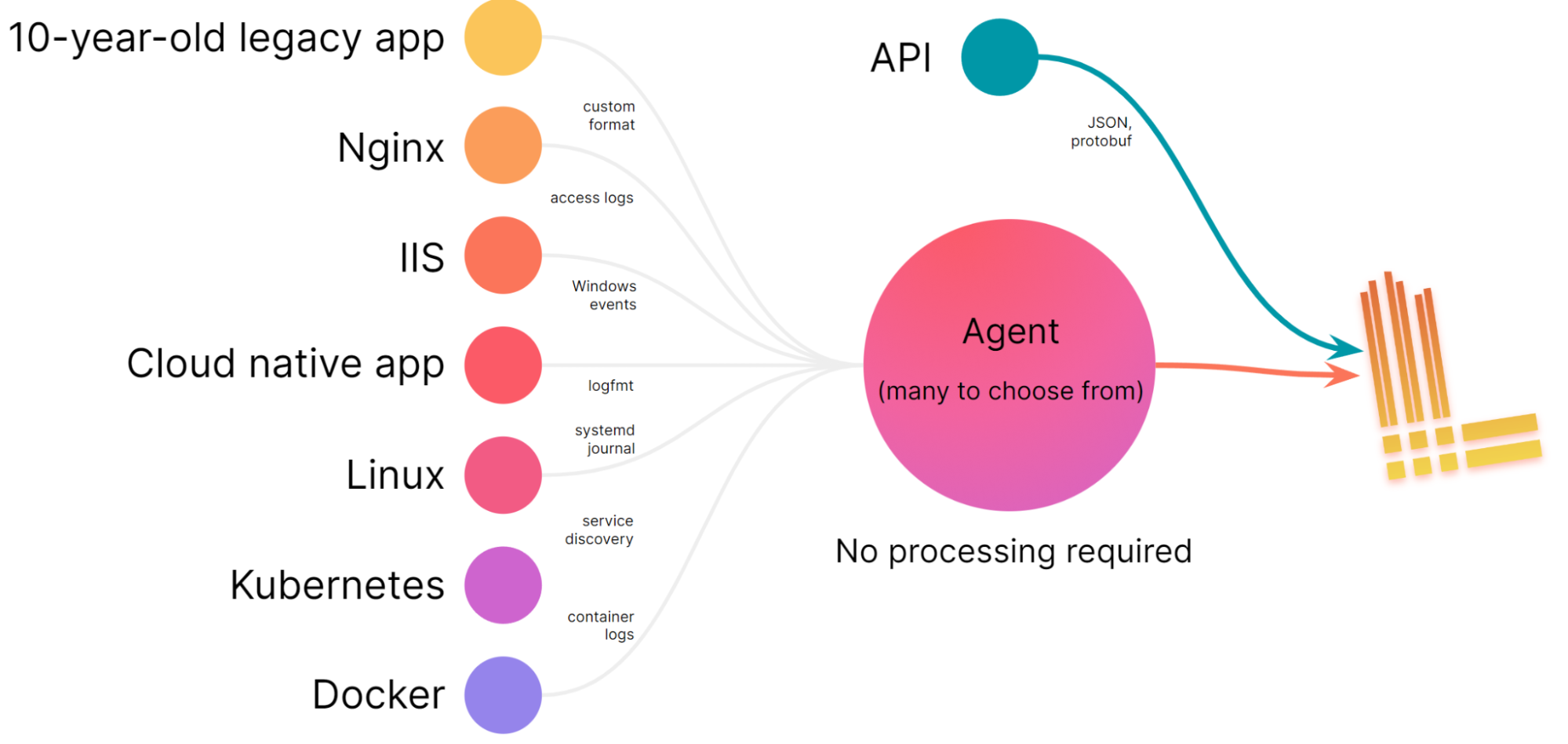
此外,我认为 Loki 成为全球 Kubernetes 集群的不二之选: Promtail 是一个简单的代理,与 Prometheus 使用的服务发现功能相同。这使得使用与组织指标相同的标签自动查找日志并对其进行分类变得非常容易。
我们的目标是制作一个简单、快速、易用的工具,让开发人员和操作人员能够使用 Prometheus 指标快速查找应用程序日志,缩小搜索范围,并透视这些指标背后的日志。
日志摄取
日志的真实世界非常混乱。几乎没有两个应用程序(即使是同一类型的应用程序)会就如何生成日志达成一致,因此我们希望 Loki 能够极大地适应这一现实问题。因此, Loki 采用了非常简单的数据模型: 它将所有内容都存储为字符串。
采用完全无模式、无结构的数据模型,可以尽可能方便地摄取数据–无需就日志格式、模式或结构达成一致。相反,Loki 采用了在查询时向日志解析和添加结构的方法,这通常被称为 “查询模式”。
我们希望 Loki 能够非常快速、经济高效地摄取日志。无延迟地获取日志信息对于制定运营决策至关重要,而且对于生成指标和警报也非常重要。Loki 没有预处理要求。它的处理速度快得惊人,同时还能保持较低的摄取成本。使用 Grafana Agent 中的默认设置,日志从创建到读取的延迟时间通常不到 2 秒。
我们还希望 Loki 能够轻松、快速、无限制地扩展。这也是它作为分布式系统构建的原因,这样可以轻松插入更多硬件,快速处理更多负载。
索引日志
数据库的一个传统复杂操作是管理大型索引。通常情况下,它们很难横向分区,因此需要使用非常昂贵、非常 "高大" 的机器,配备数百 GB 内存和 / 或极快的本地磁盘。

Loki 的设计目的是建立一个非常小的索引。我们只索引 Prometheus 风格的标签,这些标签定义了我们所说的日志流。
标签是 Loki 中的一个重要概念,因此我们将为其专门撰写一篇文章。需要注意的是,Loki 与许多其他现有日志系统的重要区别在于, Loki 不对日志行的内容进行索引。这使得索引的数量级小于数据的数量级,这意味着您可能只需要几百 MB 就能索引 20+TB 的数据。索引文件小也意味着更容易使用更多的计算;您不需要拥有数百 GB 内存的机器。
日志存储
在我看来,数据库运行中最糟糕的问题之一就是管理磁盘、磁盘空间耗尽、磁盘性能问题、磁盘故障问题以及相关的冗余模型–尤其是对于不断增长的时间序列数据。

五年前,Loki 是第一批主要使用对象存储(S3、GCS、Blob)作为主要存储机制设计和构建的数据库之一,这在当时是独一无二的。换句话说,无需管理磁盘。云提供商的对象存储系统是一项了不起的技术,通过使用它们,您可以获得难以置信的高性能、高服务水平协议、高耐用性、低成本、无忧存储。
日志查询
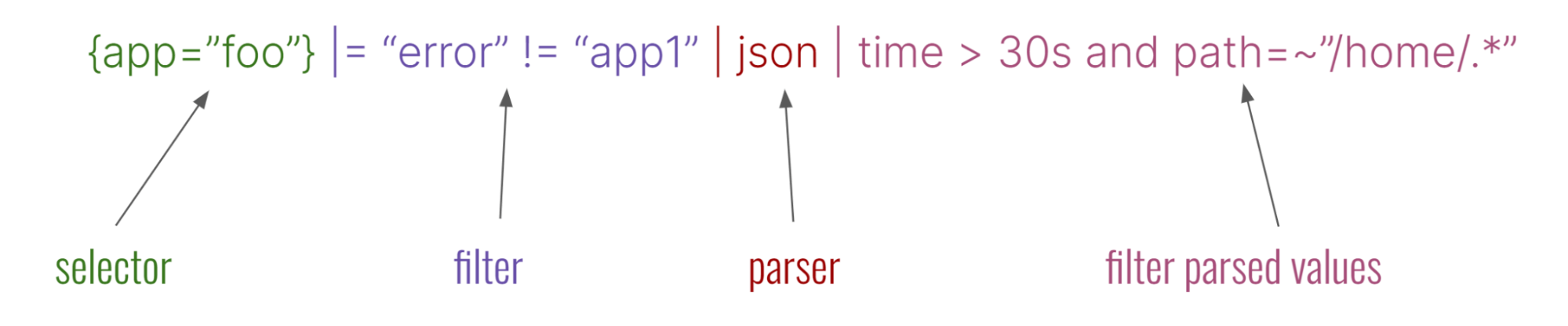
Loki 包含一个查询引擎,能够反序列化 json、解析 logfmt 或与日志行中的 pattern/regex 匹配。这样,您就可以在查询时为日志添加结构,这意味着您可以过滤、聚合、绘制图表、汇总等所有内容,而无需考虑其格式。
查询语言 LogQL 结合了命令行风格的管道和受 Prometheus 启发的函数,前者用于操作日志,后者用于创建数据的时间序列图。LogQL 背后的理念是建立一种查询语言,让熟悉使用命令行处理日志和使用 Prometheus 查询指标的用户感觉直观。

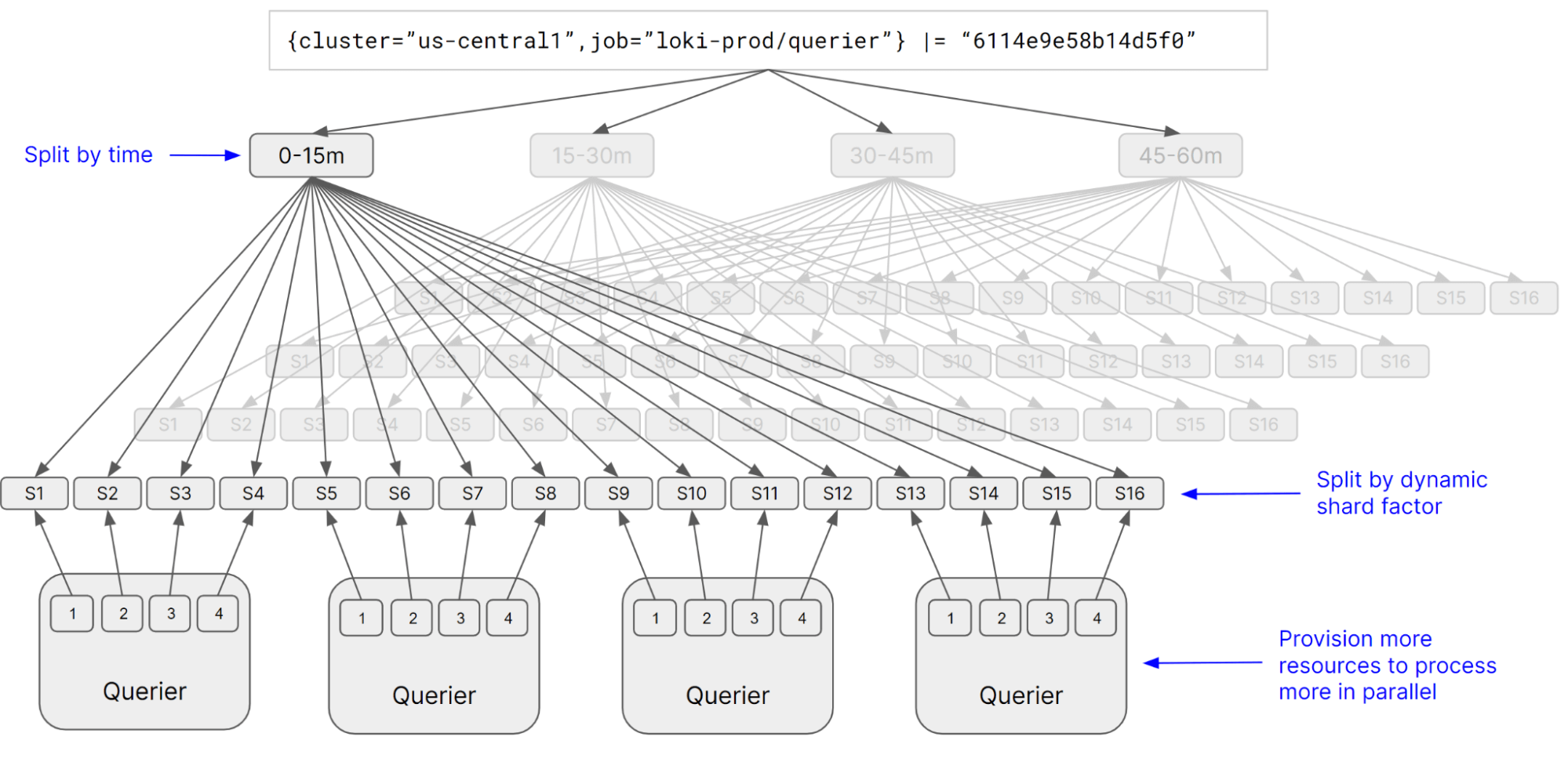
查询性能是通过大量并行化操作获得的,并行化操作就是将查询拆分成更小的子查询,这些子查询可以同时执行。一个常见的误解是,大型索引是快速查询的必要条件。但是,Loki 可以通过使用数千个并行 workers,以每秒数百 GB 的速度处理数据。通过利用 spot 实例和仅按需配置以满足查询负载,这些 Worker 也可以实现成本效益。
Loki 的设计不是为了
每个数据库都会在以下方面做出权衡:在何处花费时间和金钱、如何存储数据、如何索引数据、如何重新索引数据、如何以不同格式重新存储数据等。他们还需要权衡操作复杂性和使用复杂性(如确定模式)。数据量越大,就越需要根据目标调整数据库设计。在过去的几年中,随着 Loki 从每天摄取数百 GB 的数据增长到每天数百 TB 的数据,我学到了很多这方面的知识。
列式数据库与行式数据库
Loki 是一种面向行的数据库。这使得它在进行行操作(如插入和读取整行)时速度很快。不过,某些日志类型(如访问日志、事件日志或其他类似的高度结构化数据)可以更高效地存储在列式数据库中。
列式数据库允许您只获取原始日志行的部分内容,或只获取查询所需的列。这样就不必获取大量数据,也更容易对这类高度结构化的数据进行某些类型的分析查询。
Loki 仍能高效、快速地查询高度结构化的数据,但由于它必须获取整行数据,当您的查询开始处理 TB 或数十 TB 的日志时,列式存储可能更适合这种使用情况。
此外,由于 Loki 采用的是 “查询模式”,因此在查询时必须进行更多处理。如果您的工作负载反复查询相同的数据,甚至成百上千次,那么与预先付费构建和存储更符合查询方式的数据的数据库相比,这样做的成本会更高。
展望未来,这是我期待 Loki 继续发展的一个领域。我们已经构建了列式存储以及物化视图等原型。我认为,最终 Loki 将把行存储和列存储结合起来,以适应高度混乱和高度结构化的数据世界。
五年后的 Loki:有哪些变化
与 Loki 最初的设计相比,变化真的不大。它在工作。人们喜欢它。除非我们真的认为有必要,否则我们会努力限制复杂性的增加。但有几个地方发生了重要变化,让我们来谈谈这些地方。
更好的日志摄取和 OpenTelemetry 支持
我们扩展了存储模型,允许在日志字符串旁边存储结构化的键 = 值对。这对于更好地为 Loki 提供原生 OpenTelemetry 支持至关重要。结构化元数据还解决了一些困难的工作负载问题,在这些负载中,您需要保存一些日志行中不存在的高冗余标识符。以前,你要么将它们存储为标签,要么修改日志行以插入它们。现在,这些数据可以存储在索引之外,而无需修改日志行。
改进日志索引
从概念上讲,我们仍然只对标识您的日志流的标签进行索引,但在过去一年中,Loki 已经经历了多次索引实施的内部演变。
我们正在为 Loki 添加一些额外的 “索引”。我用这个词有点宽泛,因为我们真正要做的是利用 Bloom 过滤器来告诉 Loki 在执行查询时无需查看的地方。Bloom 过滤器是专门针对我们在 Loki 中看到的一种常见查询用例而添加的,我们称之为 “大海捞针” 查询。这是一种查找极少量日志行的查询类型,通常包含一些高度唯一的内容,如在一个非常大的数据集中的 UUID。
日志存储:过去和现在
这里变化不大。对象存储仍然很棒,我们仍然喜欢它。
查询的下一步
随着时间的推移,Loki 的查询语言已经发展到可以支持越来越多的复杂查询和用例;但与此同时,我们也发现,人们对不太复杂的查询体验的需求也在不断增长。我们目前正在构建无需任何查询语言知识的 Loki 查询原型。
我们还在研究如何改进某些类型查询的并行化,这些查询目前无法并行化,因为它们无法在不准确的情况下并行化。有一些概率数据结构可用于在大量数据中快速得出结果而非完全准确的情况。
Grafana Loki 为何如此成功
日志的世界令人难以置信地着迷,似乎没有两家公司在日志的形状、大小和数量上完全相同,也没有两家公司在如何使用这些日志上完全相同。如果有人在五年前告诉我,我会运行超过 10,000 个内核的 Loki 集群,我不知道自己会说什么。
我现在可以说的是 日志的真实世界非常混乱,每天的规模从字节到 PB 不等。我认为,像 Loki 这样的工具之所以如此成功,是因为它非常灵活。没有任何模式,同时又能从运行单个二进制文件扩展到庞大的多租户分布式系统,这使得 Loki 成为一个非常适合大量用户的解决方案。
通过这个 Loki 博客系列,我希望能提供有价值的内容,让更多人得出同样的结论。请在下周与我一起重温 Loki 标签简明指南!
