DRBD 简介
本文最后更新于:2025年2月22日 下午
描述
数据镜像软件 DRBD 介绍
分布式块设备复制(Distributed Replicated Block Device),简称 DRBD,它是一种基于软件的、基于网络的块复制存储解决方案,主要用于服务器之间的磁盘、分区、逻辑卷等进行数据镜像。当用户将数据写入本地磁盘时,还会将数据发送到网络中另一台主机的磁盘上,这样本地主机(主节点)与远程主机(备节点)的数据就可以保证实时同步,当本地主机出现问题,远程主机上还保留着一份相同的数据,可以继续使用,保证了数据的安全。
DRBD 的基本功能
DRBD 的核心功能就是数据的镜像,其实现方式是通过网络来镜像整个磁盘设备或磁盘分区,将一个节点的数据通过网络实时的传送到另一个远程节点,保证两个节点间数据的一致性,这有点类似于一个网络 RAID1 的功能。对于 DRDB 数据镜像来说,它具有如下特点:
- 实时性。当应用对磁盘数据有修改操作时,数据复制立即发生。
- 透明性。应用程序的数据存储在镜像设备上是透明和独立的。数据可以存储在基于网络的不同服务器上。
- 同步镜像。当本地应用申请写操作时,同时也在远程主机上开始进行写操作。
- 异步镜像。当本地写操作已经完成时,才开始对远程主机进行写操作。
DRBD 的构成
DRBD 是 Linux 内核存储层中的一个分布式存储系统,具体来说有两部分构成,一个是内核模板,主要用于虚拟一个块设备;一个是用户空间管理程序,主要用于和 DRBD 内核模块通信,以管理 DRBD 资源,在 DRBD 中,资源主要包含 DRBD 设备、磁盘配置、网络配置等。
DRBD 设备在整个 DRBD 系统中位于物理块设备之上,文件系统之下,在文件系统和物理磁盘之间形成了一个中间层,当用户在主用节点的文件系统中写入数据时,数据被正式写入磁盘前会被 DRBD 系统截获,同时,DRBD 在捕捉到有磁盘写入的操作时,就会通知用户空间管理程序把这些数据复制一份,写入到远程主机的 DRBD 镜像,然后存入 DRBD 镜像所映射的远程主机磁盘。
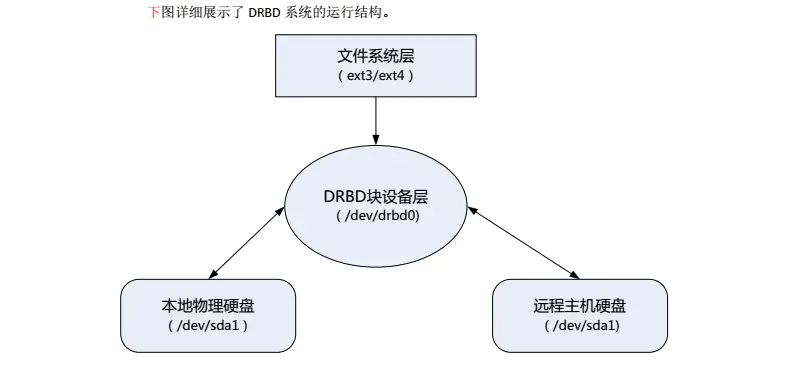
**DRBD 负责接收数据,把数据写到本地磁盘,然后发送给另一个主机。** 另一个主机再将数据存到自己的磁盘中。DRBD9 以前每次只允许对一个节点进行读写访问,这对于通常的故障切换高可用性集群来讲已经足够用了。DRBD9 及以后的版本将支持两个节点进行读写存取。
DRBD 的主要特性
DRBD 系统在实现数据镜像方面有很多有用的特性,我们可以根据自己的需要和应用环境,选择适合自己的功能特性。下面依次介绍 DRBD 几个非常重要的应用特性。
- 单主模式:这种是最经常使用的一种模式,主要用在高可用集群的数据存储方面,解决集群中数据共享的问题,在这种模式下,集群中只有一个主节点可以对数据进行读写操作,可以用在这种模式下的文件系统有 ext3、ext4、xfs 等。
- 双主模式:这种模式只能在 DRBD8.0 以后的版本中使用,主要用在负载均衡集群中,解决数据共享和一致性问题,在这种模式下,集群中存在两个主节点,由于两个主节点都有可能对数据进行并发的读写操作,因此单一的文件系统就无法满足需求了,此时就需要共享的集群文件系统来解决并发读写问题。常用在这个模式下的文件系统有 GFS、OCFS2 等,通过集群文件系统的分布式锁机制就可以解决集群中两个主节点同时操作数据的问题。
复制模式
DRBD 提供了三种不同的复制方式,分别是:
- 协议 A,只要本地磁盘写入已经完成,数据包已经在发送队列中,则认为一个写操作过程已经完成。这种方式在远程节点故障或者网络故障时,可能造成数据丢失,因为要写入到远程节点的数据可能还在发送队列中。
- 协议 B,只要本地磁盘写入已经完成,并且数据包已经到达远程节点,则认为一个写操作过程已经完成。这种方式在远程节点发生故障时,可能造成数据丢失。
- 协议 C,只有本地和远程节点的磁盘已经都确认了写操作完成,写认为一个写操作过程已经完成。这种方式没有任何数据丢失,就目前而言应用最多、最广泛的就是协议 C,但在此方式下磁盘的 I/O 吞吐量依赖于网络带宽。建议在网络带宽较好的情况下使用这种方式。
DRBD 的企业应用场景
生产场景中会有很多基于高可用服务器对 drbd 的数据同步解决方案。
例如:
- 存储数据同步:
heartbeat+drbd+nfs/mfs/gfs - 数据库数据同步:
heartbeat+drbd+mysql/oracle等。
实际上 drbd 可以配合任意需要数据同步的所有服务的应用场景。
安装与配置
配置 DRBD
我们在 /etc/drbd.d 下面创建一个 mydb.res 文件。下面是两台 DRBD 主机节点配置文件的简单示例
1 | |
DRBD 的管理与维护
DRBD 状态
在任意节点上查看节点状态
登陆任意 drbd 节点,然后执行 cat /proc/drbd 命令,输出结果如下:
1 | |
对输出的含义解释如下(常见的):
cs 连接状态:
-
StandAlone 独立的:网络配置不可用。资源还没有被连接或者被管理员断开(使用
drbdadm disconnect命令),或者是由于认证失败或者是脑裂的情况。 -
Disconnecting 断开:断开只是临时状态,下一个状态将是 StandAlone 独立的。
-
Unconnected 悬空:是尝试连接前的临时状态,可能的下一个状态为 WFconnection 和 WFReportParams
-
Timeout 超时:与对等节点连接超时,也是临时状态
-
WFConnection 等待和对等节点建立网络连接
-
WFReportParams: 已经建立 TCP 连接,本节点等待从对等节点传来的第一个网络包
-
Connected 正常连接
-
SyncSource: 以本节点为同步源的同步正在进行
-
SyncTarget: 以本节点为同步目标的同步正在进行
-
ro: 即 roles,本地节点和远程节点的角色,第一次启动 drbd 时,两个 drbd 节点默认都处于 Secondary 状态。
-
ds: 即 disk states, 本地和远程节点的硬盘状态,“Inconsistent/Inconsistent” 即 “不一致 / 不一致状态”,表示两个节点的磁盘数据处于不一致状态
-
C: 表示所使用的协议时 C
以下六个表示的是 I/O 状态标记
r或s: 表示 I/O 操作正在进行, s 表示 I/O 挂起,正常 r-或a: a 表示延迟后再同步-或p:p 表示因为对等层启动同步挂起而引起的数据再同步的情况-或u:u 表示因为本地启动同步挂起而引起的数据再同步的情况-或d,b,n,a: d 表示因为 drbd 内部原因引起的 I/O 阻塞,类似一种过渡磁盘状态;b 表示备用设备 I/O 正在阻塞;n 表示网络套接字的阻塞;a 表示同时发生 I/O 设备阻塞和网络阻塞-或s: s 表示当挂起更新的活动日志时的标记。
以下的标记表示的是性能指标(主要前面的 4 项)
ns: 即 network send, 表示通过网络发送到对等节点的数据量,单位是 kbytenr: 即 network receive, 表示通过网络接收来自对等节点的数据量dw: 即 disk write, 表示写到本地资产的网络数据dr: 即 disk read, 表示从本地磁盘读出的网络数据
DRBD 主备节点切换
在系统维护得时候,或者在高可用集群中,当主节点出现故障时,就需要将主备节点得角色互换。主备节点切换有两种方式,分别是停止 drbd 服务切换和正常切换。
1. 停止 DRBD 服务切换
关闭主节点服务,此时挂载的 DRBD 分区就自动在主节点卸载了,操作如下:
1 | |
然后查看备用节点的 DRBD 状态:
1 | |
从输出可以看到,现在的主节点的状态变为 “unknown” , 接着在备用节点执行切换命令:
1 | |
因此,必须在备用节点执行如下命令:
1 | |
或者
1 | |
现在就正常切换了,接着查看此节点的状态。可以看出,原来的备用节点已经处于 primary 状态,而原来的主节点由于 DRBD 服务未启动,还处于 Unknown 状态,在原来的主节点服务启动后,会自动变为 Secondary 状态,无需在原来的主节点上再次执行切换到备用节点的命令
最后,在新的主节点上挂载 DRBD 设备完成主备节点的切换
2. 正常切换
1 | |
脑裂的处理
drbd 的对等节点如果不在线的话,即主节点的数据更改如果无法及时传送到备节点达到一定时间,会造成数据不一致,即使故障节点离线后恢复,drbd 可能也不能正常同步了。或者另外一种情况,主备都在线,但心跳网络断了而出现脑裂,两个节点都认为自己是主节点,也会造成两个节点的数据不一致,这样需要人工干预,告诉 drbd 以哪个节点为主节点,或者在 dbrd 配置脑裂的行为。下面是长时间备节点不在线后出现的情况:
查看备用节点的状态:
1 | |
- cs (连接状态),孤立的
- ro (角色),
Secondary/Unknown - ds (磁盘状态) 是
uptodate/unknown, 本地节点处于正在更新状态,而对等节点为 unknown 状态。 从以上可以看出,备节点发生了 drbd 脑裂。
发生脑裂后,需要认为确认哪个节点有最新的数据,那么就以哪个节点为主,比如发生脑裂后,主节点 master-drbd 数据最新,那么就以 master-drbd 节点数据为准,然后进行恢复和手动同步。
手动恢复脑裂
步骤如下:
- 在 slave-drbd 从节点上设置为从节点,并丢弃资源数据
1 | |
- 在 master-drbd 主节点上手动连接资源:
[root@master-drbd /]#drbdadm connect mydb
这样,就解决了脑裂的问题,主从节点又开始同步数据了
