「译文」Loki 简明指南:如何处理失序和较旧的日志
本文最后更新于:2025年2月22日 下午
✍️Author: Ed Welch
📝Description:
了解 Grafana Loki 中的无序摄取是如何工作的,以便您在需要日志聚合系统摄取较旧日志时知道该如何处理。
在本周的 "Loki 简明指南" 中,我想重点谈谈 Grafana Loki 历史上的一个有趣话题:摄取无序日志。
参与这个项目有一段时间的人可能还记得,Loki 曾经会拒绝任何比它已经接收到的日志行更早的日志。这当然是对 Loki 内部结构的一个很好的简化,但也给现实世界中的许多用例带来了很大的不便。
正是由于这种不便,我们在几年前决定解决这个问题。当时,欧文 - 迪尔(Owen Diehl)写了一篇不错的博客,其中详细介绍了解决方案中的工程考虑因素。如果你想了解解决方案是如何构建的,这篇文章值得一读,但它的高度概括是这样的: 工程设计总是充满了权衡取舍,我们试图在性能、运营成本和功能之间取得平衡,从而开发出我们认为最适合 Loki 及其用户的解决方案。
在今天的文章中,我想谈谈这些取舍–不是为什么我们要这样做,而是如何影响您使用 Loki 的方式。我将使用一些动画来帮助您直观地了解其工作原理,并解释您在将旧版日志导入 Loki 时应该注意的事项。请系好安全带,做好准备: “订阅简明指南!”
无序摄取的工作原理
正如我在本系列第一篇文章中所描述的,Loki 的设计侧重于在摄取时实现快速和低成本。一般来说,它还希望能处理最近的数据。(也就是说,它所接收的数据的时间戳是在当前时间的几秒到几分钟之内)。因此,我们采用失序解决方案的主要目的是确保 Loki 在合理的时间内接受并存储延迟日志。
我们将 "合理时间" 定义为一小时。从技术上讲,它被定义为 max_chunk_age/2,但您应该像我们在 Grafana Labs 所做的那样,将 max_chunk_age 设为两小时(稍后将详细介绍)。Loki 的无序日志摄取规则是这样的:
任何日志都将被接受并存储。任何比某个数据流收到的最近日志早一个小时以上的日志都会被拒绝,并显示错误信息,内容如下 “Entry too far behind.”。
上述声明中有两个非常重要的概念,它们是导致 Loki 如何接受较早日志的最主要原因。我用粗体标出了这两个概念:"最近日志" 和 “流”。
顾名思义,"最近日志" 指的是 Loki 收到的具有最新时间戳的日志。听起来很简单,对吗?但是,如果将其与 "for a stream" 配对使用,就会出现混乱。这是因为 Loki 会逐个流确定最新日志,所以你不能自动假定你的流都是在同一时间对齐的。
也许一些更简陋的动画会对您有所帮助!首先让我们来看一个单一的数据流:

现在,让我们将该示例扩展到多个数据流:
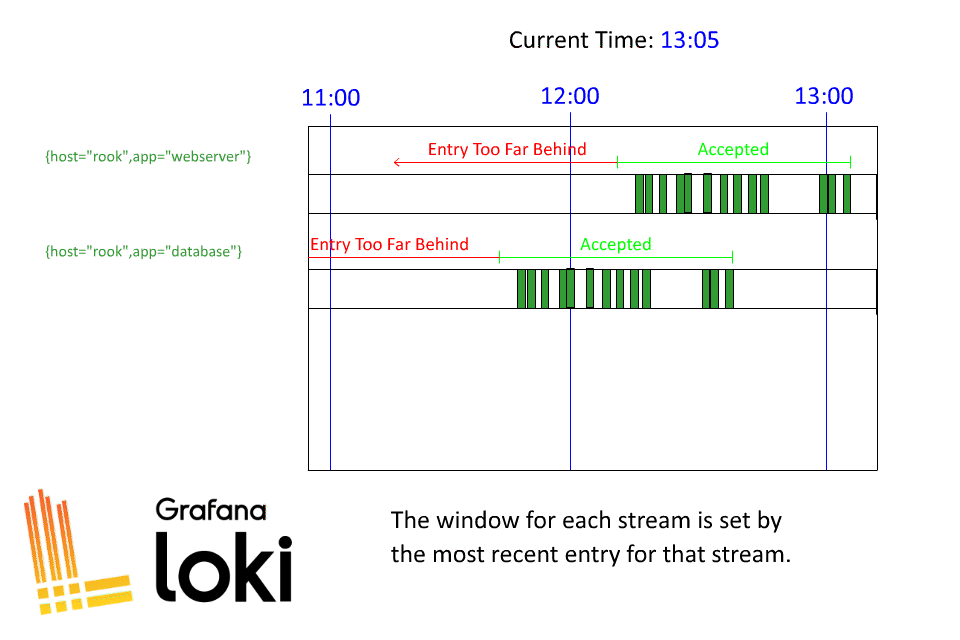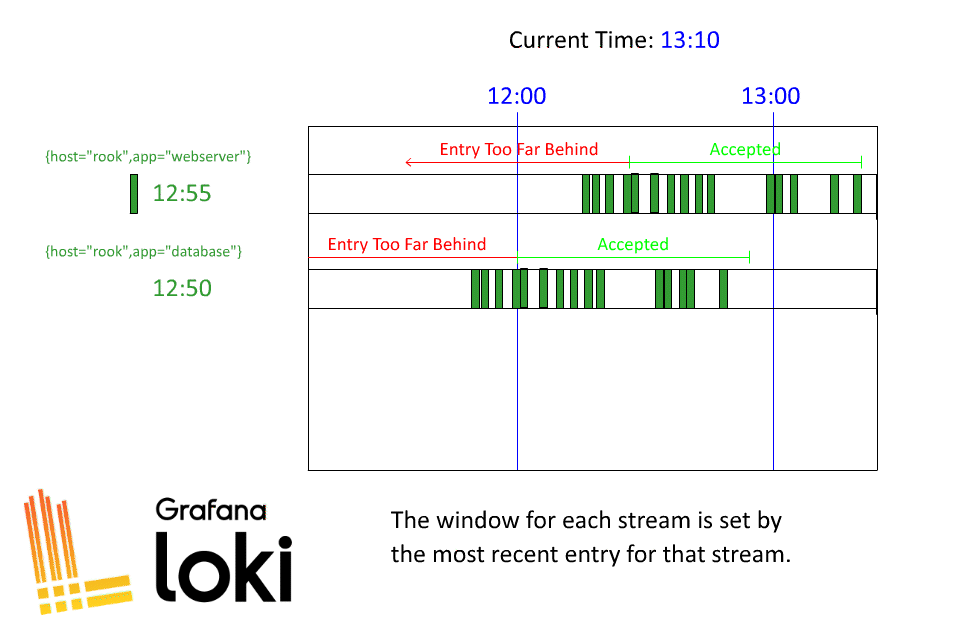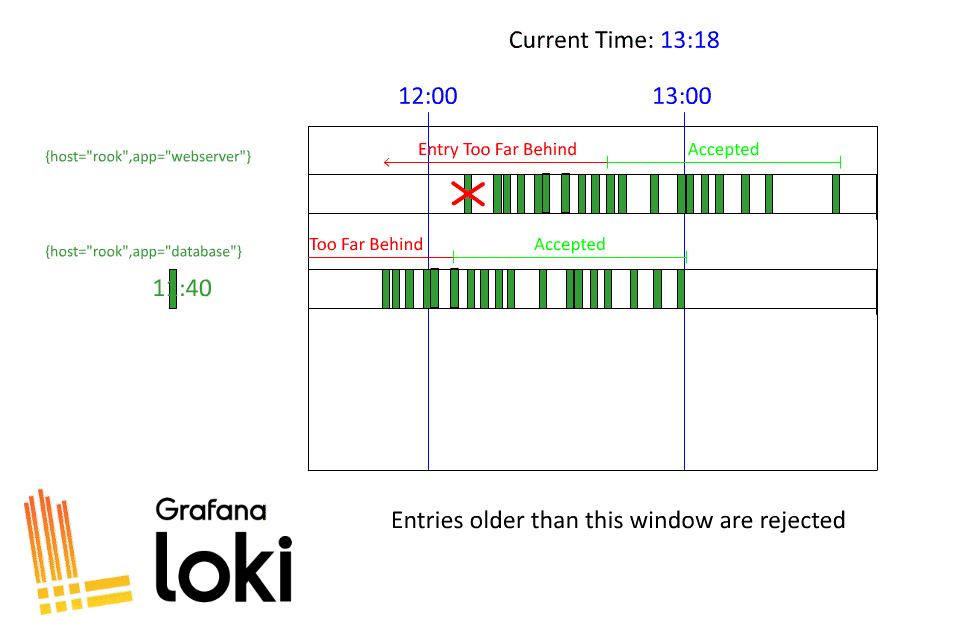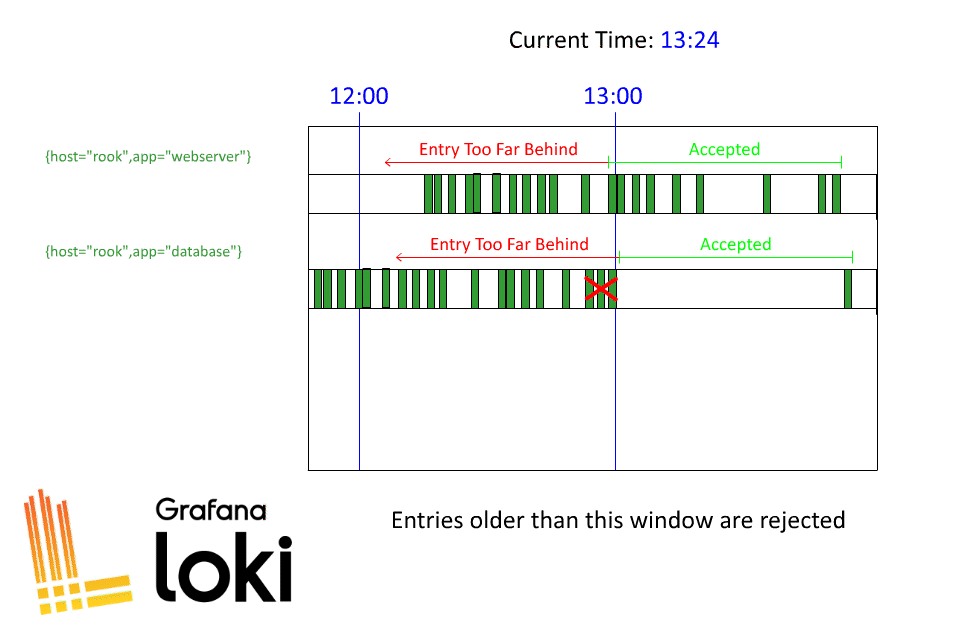
希望这有助于澄清洛基是如何接收旧日志的!
重要配置
有几项重要配置与 Loki 如何处理日志条目的排序有关,接下来让我们看看这些配置。
摄取旧数据
在 Loki 配置的 limits_config 部分,有两个设置可以控制旧数据的摄取:
1 | |
有趣的是,这些默认值在很大程度上与 Loki 能够将亚马逊 DynamoDB 用作索引类型的传统有关。使用 DynamoDB 时,Loki 会更改旧表的吞吐量配置以节省成本,这意味着它不能再接受旧时间范围的数据。
自几年前发布 Loki 2.0 以来,我们已经不再使用这些外部索引类型。如果您希望向 Loki 发送超过一周的日志,或任何时间段的日志,请随时更改 reject_old_samples: false 或将窗口设置得更大。
失序窗口
我在开篇中提到了失序数据的窗口:
max_chunk_age 可以在 ingester config 中找到。
这里的默认值是两小时。我强烈建议增加该值,以创建更大的失序窗口。在 Grafana 实验室,我们并不以这种方式运行 Loki,因此我无法轻易告诉您可能会面临哪些挑战。我建议尝试找到一种使用标签来分离数据流的方法,这样就可以分别摄取它们。
如果您决定不采纳我的建议,请务必增加 query_ingesters_within 的值,使其与您的 match_chunk_age 匹配,以确保这些数据是可查询的。
获取旧数据时的查询注意事项
在向 Loki 采集旧数据时,有一个重要的注意事项。具体来说,如果您希望 Loki 摄取距离当前时间超过两个小时的数据,这些数据将无法立即进行查询。
这是因为我们在上一节中提到的配置:query_ingesters_within。也许这个配置的名称有点令人困惑,但它的基本意思是 “只查询从当前时间起在这个时间窗口内的摄取者”。这里的默认值是三小时;从当前时间算起的三小时内的任何数据查询都将发送给摄取者,而该窗口之外的任何数据都不会发送。
之所以采用这种方式构建 Loki,是因为我们知道摄取器允许的 max_chunk_age 是两个小时。因此,我们可以不要求摄取器提供我们知道它们不会有的数据,从而大大减少摄取器的损耗。换句话说,如果你要查询昨天的日志,我们就不会向摄取器索要,因为它不应该有昨天的日志。
您在这里可能会遇到的问题是,如果您发送昨天的 Loki 日志,那么这些日志就会在摄取器中,直到它们被刷新到存储空间(最多两个小时)。在刷新之前,它们不会返回到查询结果中。
您可以将此配置值改为更大的值,比如 48 小时,这样您就可以查询昨天的日志,因为它们是在今天被摄取的。但我真的不建议这样做,因为这将迫使 Loki 在 48 小时内查询所有查询结果。这将迫使您的摄取器做更多的工作,使它们的运行成本更高。在正常情况下,摄取器在两小时内不会有任何数据,这也会损害摄取器的性能。
如果您要为回填操作摄取旧数据,我建议您只需等待两小时,让所有数据都刷新即可。如果您在正常操作中摄取较旧的日志,并且不喜欢等待,那么您可以考虑更改 query_ingesters_within ,但要意识到这可能会在成本和性能上带来一些负面的操作权衡。
结论
我希望这篇文章有助于解释 Loki 中的失序和旧日志摄取是如何工作的。我们确实努力在支持 Loki 的典型用例和适应其他用例之间取得适当的平衡 - 所有这些都没有增加成本或牺牲性能,至少我们尽了最大努力。
请在下周再次访问我们的 Loki 指南!
