「译文」Grafana Loki 简要指南:关于标签您需要了解的一切
本文最后更新于:2025年2月22日 下午
✍️Author: Ed Welch
📝Description:
在 "Loki 简明指南" 的第二部分,您将了解如何在我们最喜欢的日志数据库中正确使用标签。
欢迎阅读 "Loki 简明指南" 的第 2 部分,这是一个多部分系列,我将在这里介绍有关我们最喜爱的日志数据库的一些最重要的主题: Grafana 洛基。值此 Loki 五周年之际,我觉得这是一个很好的机会来总结一下它是如何工作、如何构建、如何运行等一些重要部分。正如本系列的名称所示,我将尽可能简明扼要地进行总结。
在 上周博客 中,我简要介绍了日志聚合工具,并将 Loki 的索引描述为 “Prometheus 风格的标签,这些标签定义了我们所说的日志流”。但这究竟是什么意思呢?在本周的博客中,我们将深入探讨 Loki 的标签、它们的工作原理、这些年来的变化,以及使用 Loki 索引发挥最大功效所需的知识。
标签在 Grafana Loki 中的工作原理
标签 既是 Loki 对传入数据进行分片的键空间,也是用于在查询时查找日志的索引。正确使用标签对应用程序的成功至关重要,因此我很自然地选择在本系列文章中专门讨论标签的工作原理和最佳实践。
从概念上讲,标签很简单;它们是一组任意的键值对,您可以在摄取时将其分配给日志。但在实践中,它们会给新用户带来一些问题。人们可能会根据使用其他数据库的经验,先入为主地认为 Loki 的索引应该如何工作,或者他们可能会试图在 Loki 标签中使用与在 Prometheus 中使用度量标准相同的基数。
那么,一个很好的起点或许就是举例 / 演示 Loki 中的标签是如何工作的。想象一下日志数据的来源 - 生成日志的应用程序或系统。多年前,这可能是一台机器,它可能有一个类似 "Rook" 的名字,是一个在 SPARC 硬件上运行 Solaris 的 Unix 系统。事实上,它可能至今还在你的梦中萦绕。
让我们把这台服务器上的日志发送给 Loki。为此,我们将分配一个非常基本的单一标签:
{host=”rook”}
Loki 将接收这些数据,并开始为该数据流构建数据块。
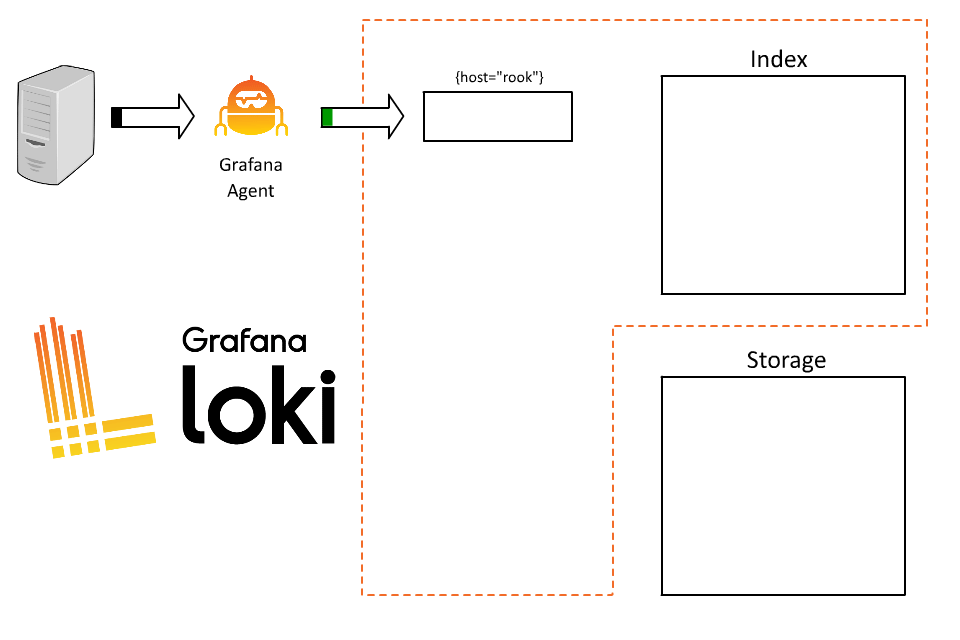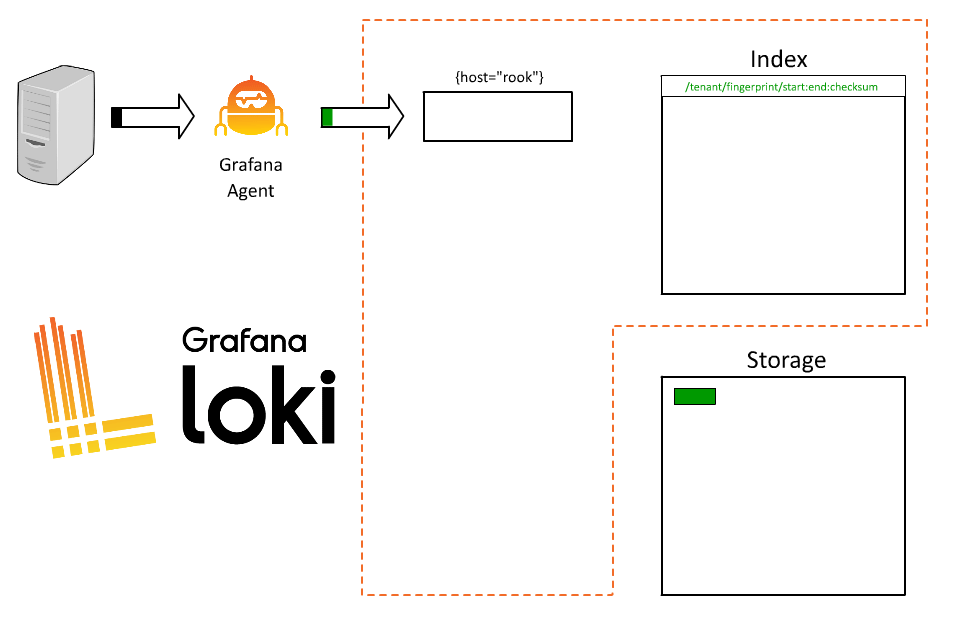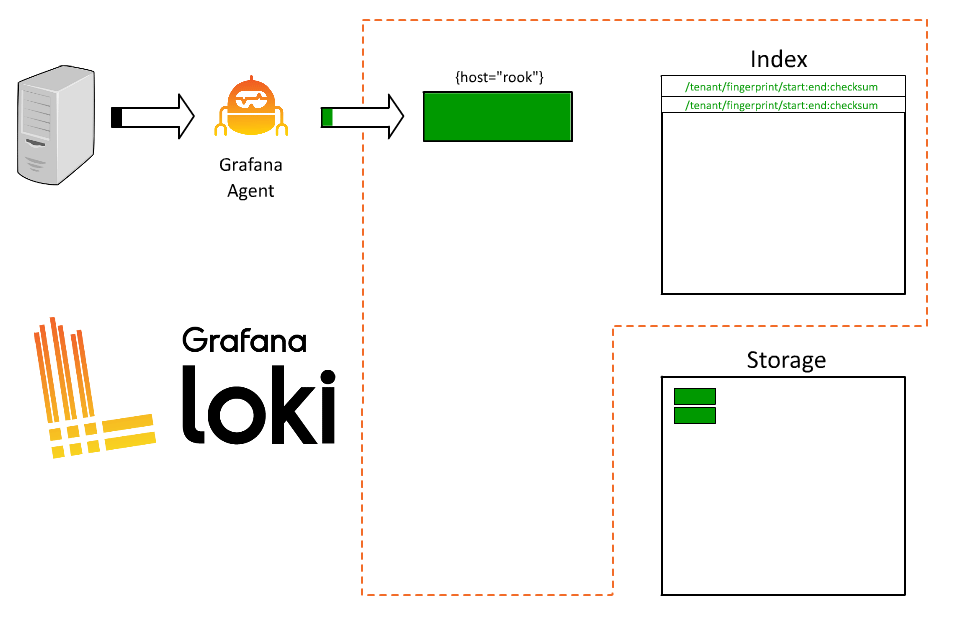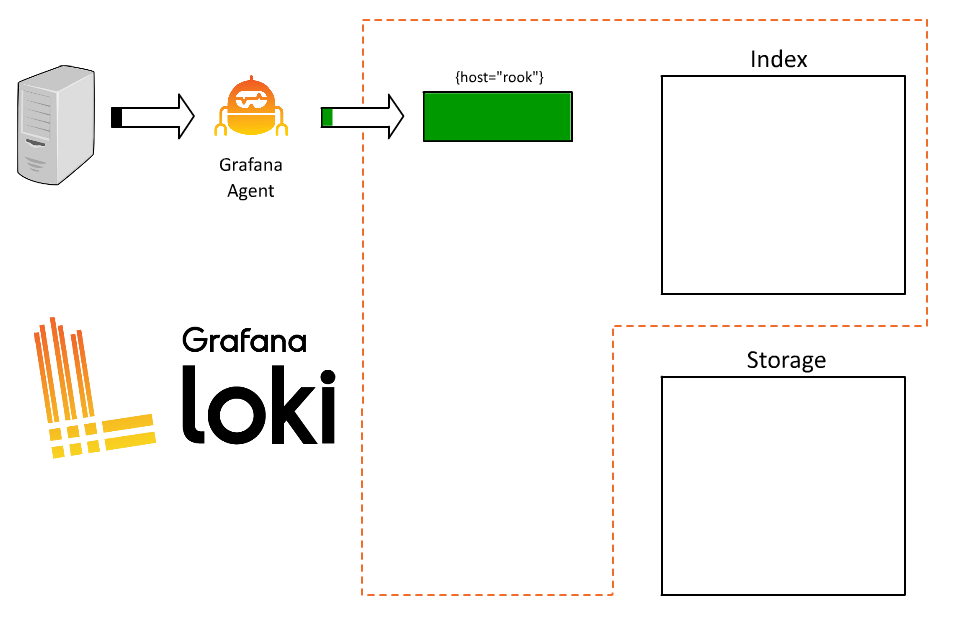
但这里有一个问题。Rook 运行着大量应用程序,我们的每次查询都必须查询所有应用程序。因此,用户在试图了解哪些日志来自哪个系统时会感到非常沮丧,查询速度也会变慢。
让我们使用标签来改善这种情况。
1 | |
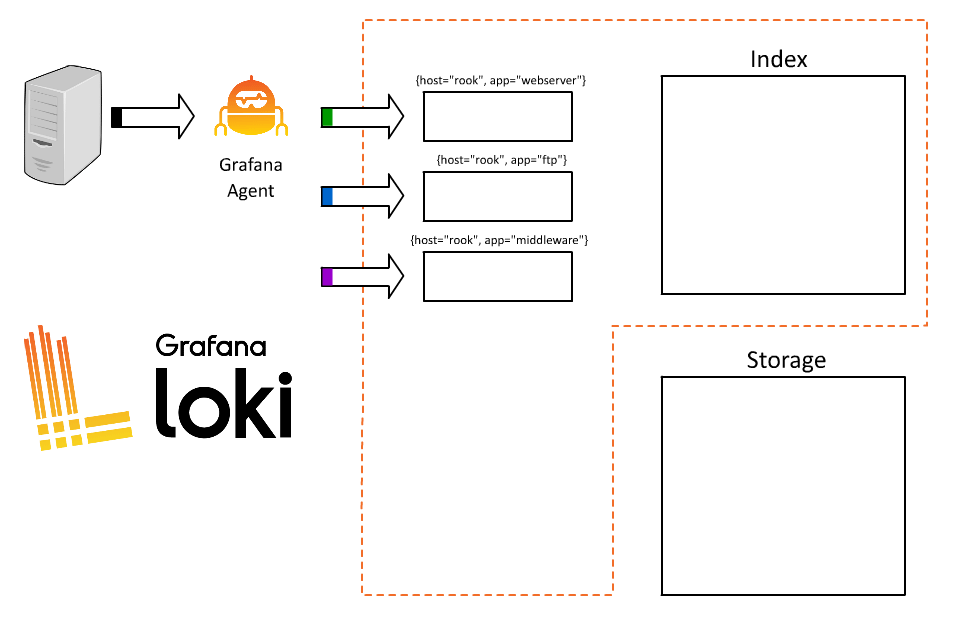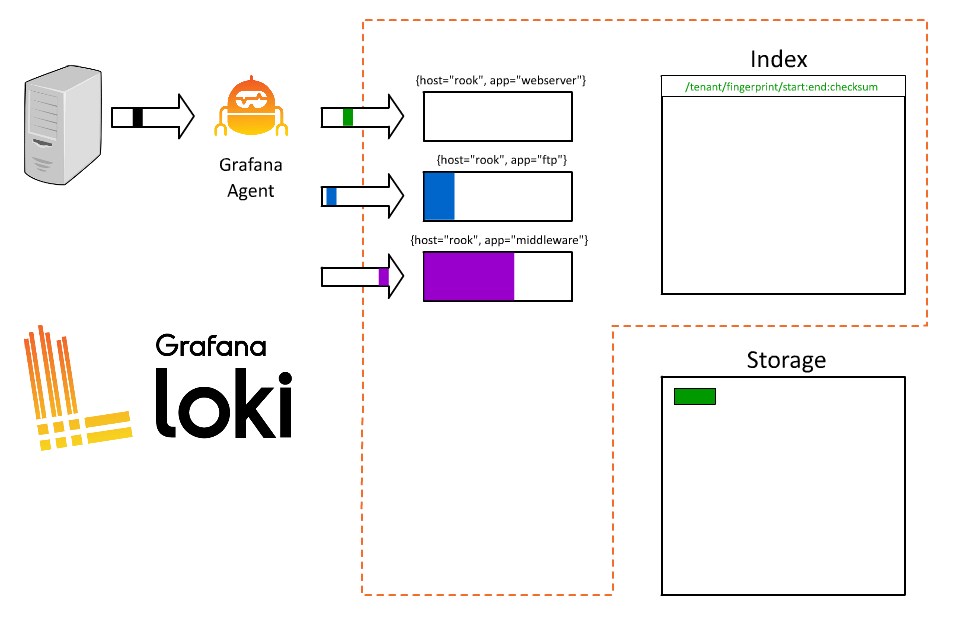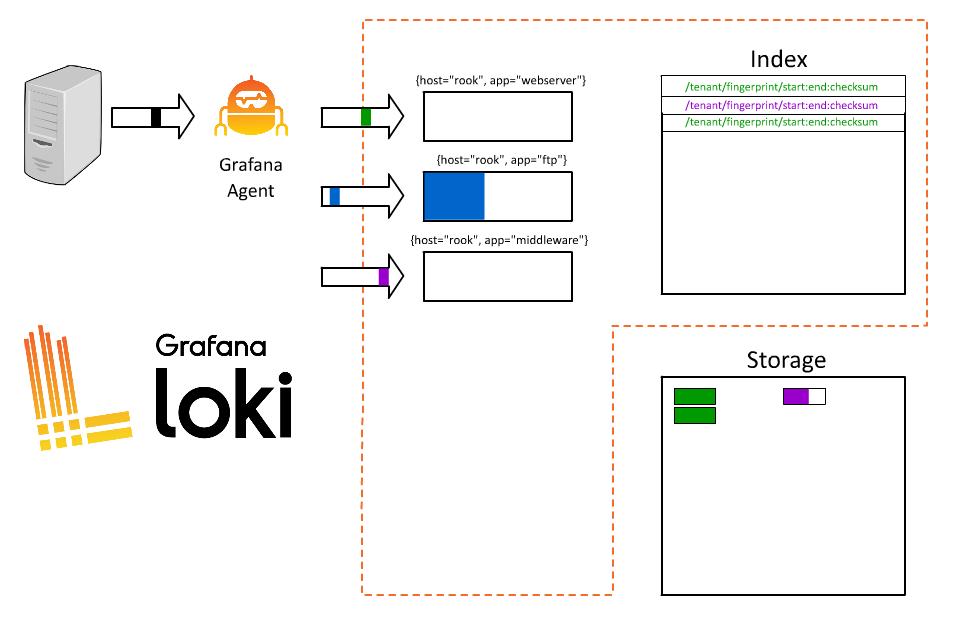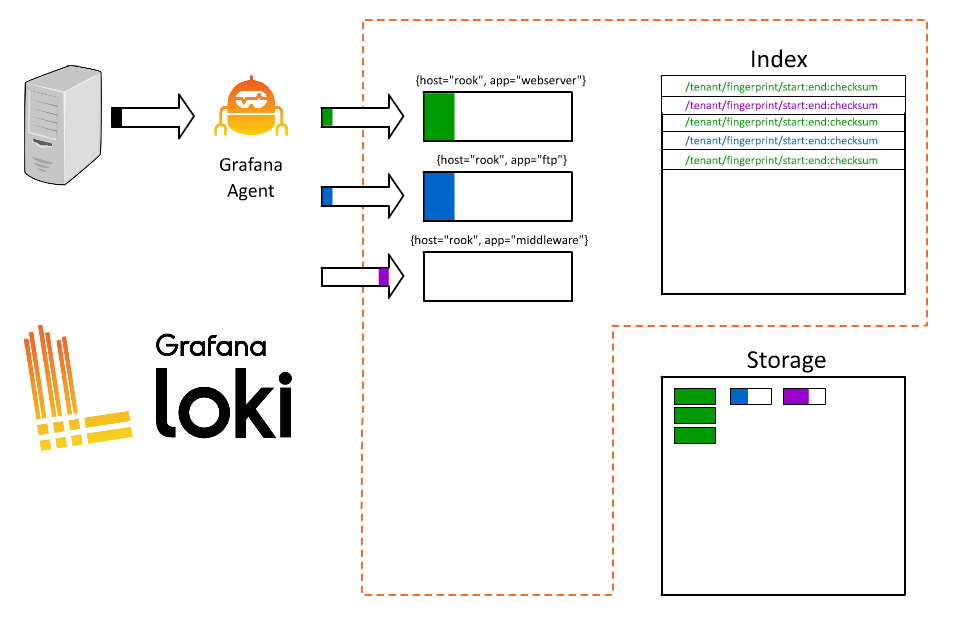
好,太好了。现在每个人都可以查询了,而且他们只需获取其特定应用程序的日志。但为什么要到此为止呢?我以前也玩过这种游戏;索引中的内容越多越好,不是吗?我们的系统要处理大量订单,为什么不把订单 ID 也编入索引呢?

嗯,我想我把它弄坏了。
出了什么问题?通过引入订单 ID 作为标签,我们把来自 Rook 的所有日志都分割成了数以千计的短实时流。由于每个流都会写入一个单独的文件,因此 Loki 会创建成千上万个小文件,每个文件都需要在索引中添加一个条目(因此也需要空间)。
Loki 的设计或构建并不是为了支持高基数标签值。事实上,它的设计初衷恰恰相反。它是为非常长期的数据流和非常低的标签基数而设计的。在 Loki 中,使用的标签越少越好。
以下是一些好标签的特质:
- 它们描述了基础设施,可能包括区域、集群、服务器、应用程序、命名空间或环境。
- 它们是长期的 , 标签值应永久生成日志,或至少持续几个小时。
- 它们便于直观查询。
最后一条非常重要。标签是控制数据查询量的唯一因素,因此必须使用易于学习、查询时直观的标签。
有什么变化?
从根本上说,Loki 使用标签的方式与五年前相同,使用标签的建议也基本未变。不过,我们在用户遇到摩擦的几个方面进行了改进,让我们来看看这些方面。
单个数据流中的数据过多
定义数据流的键值对集合也定义了在 Loki 中对数据进行分割或分片的键空间。键值对集散列为一个数字,该数字决定了散列环上的一个点。而这个点决定了由哪个摄取器接收该数据流的数据。在过去的几天里,我花了大约 100 个小时学习如何创建动画,因为在这种情况下,我确实认为 “一张图片胜过千言万语”(即使这些话是我写的):
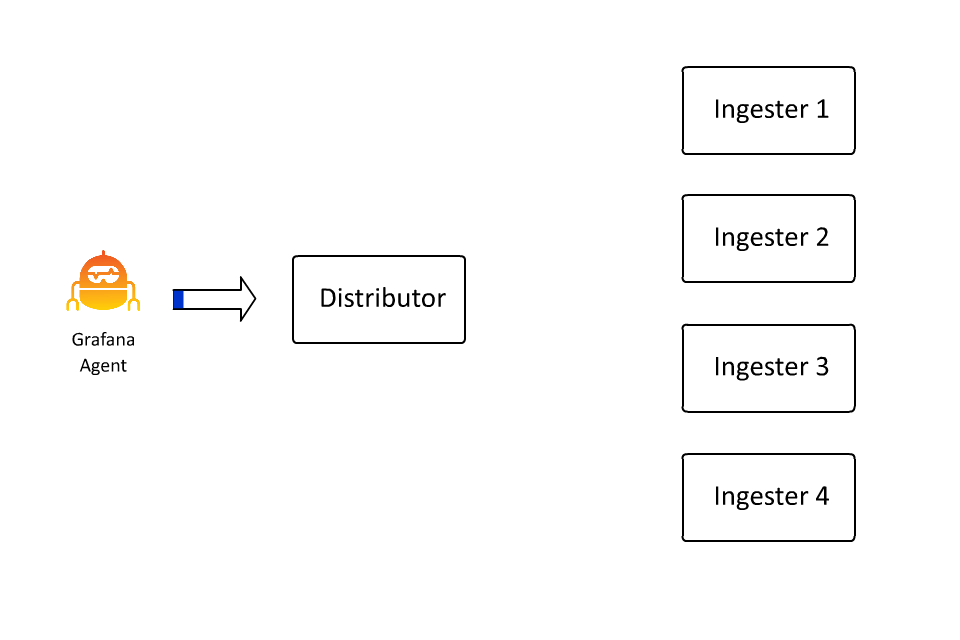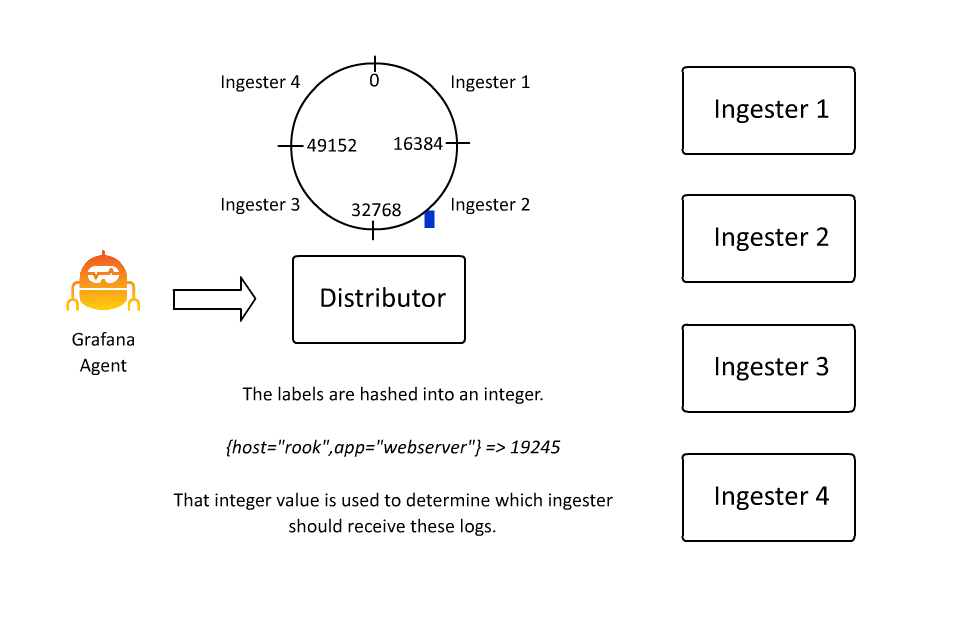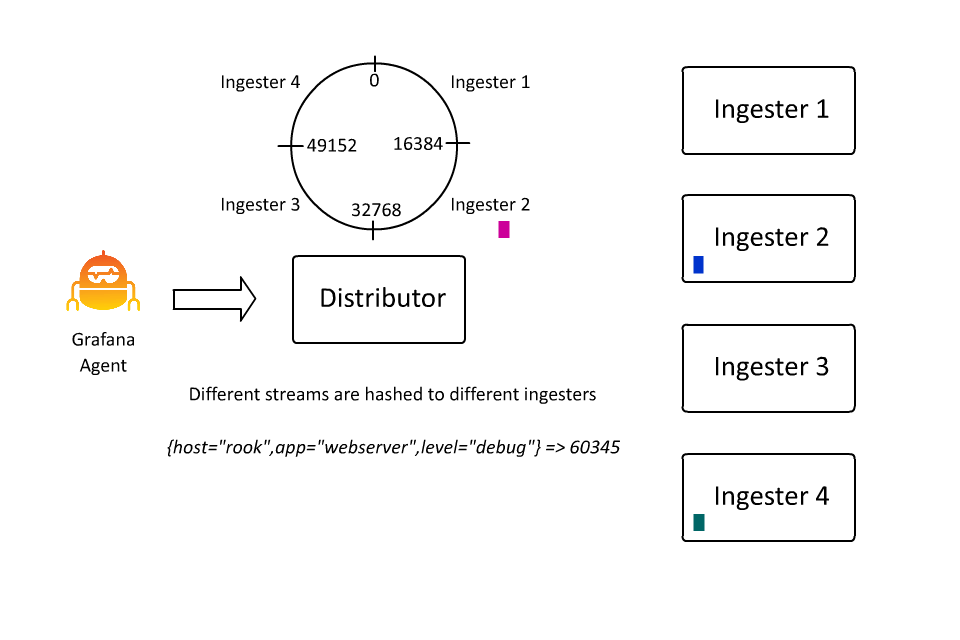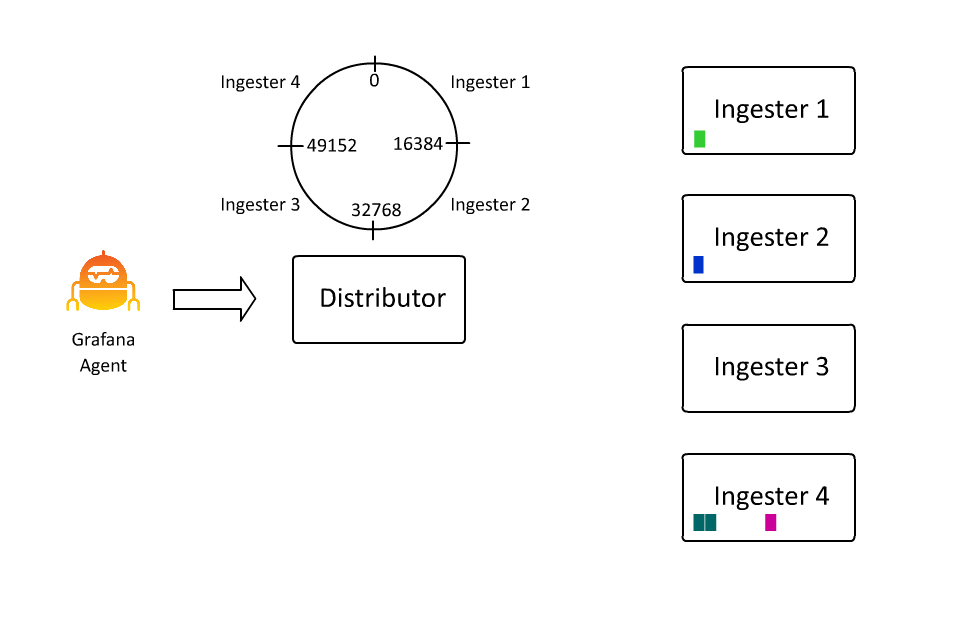
这样,Loki 就可以通过插入越来越多的机器,继续接收越来越多的数据,因为接收器只负责所有数据流的一个子集。然而,这里存在一个问题: 如果数据流变得非常大怎么办?
当从 Pub/Sub 或 Kafka 等系统或其他可以聚合大量日志的系统中提取日志时,这种情况最为常见。由于 Loki 关键空间中的关键是流,如果流的体积无限制地增长,就要求拥有该流的摄取者也垂直扩展,使用更多的 CPU/RAM 来处理它。
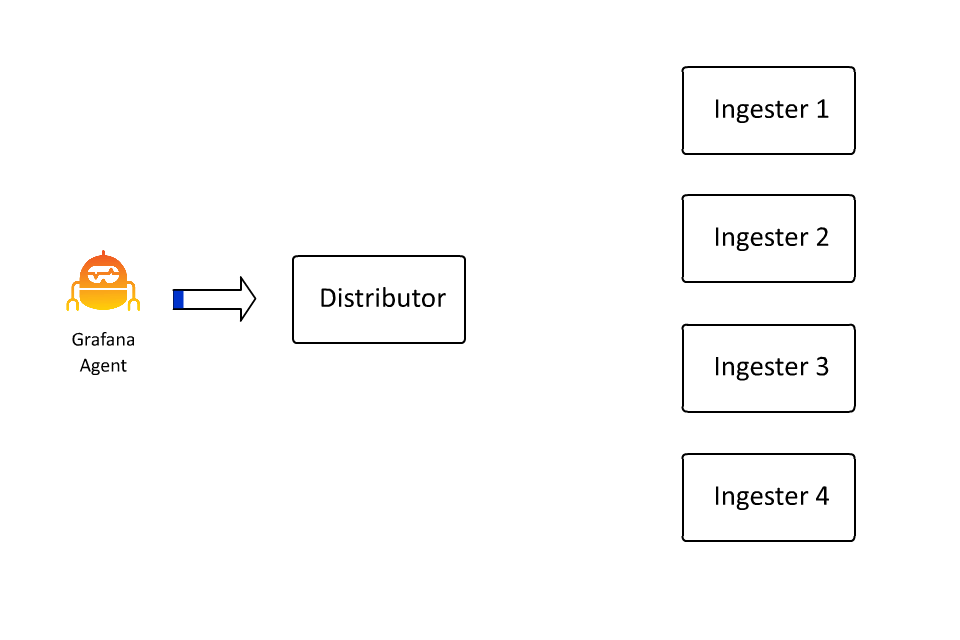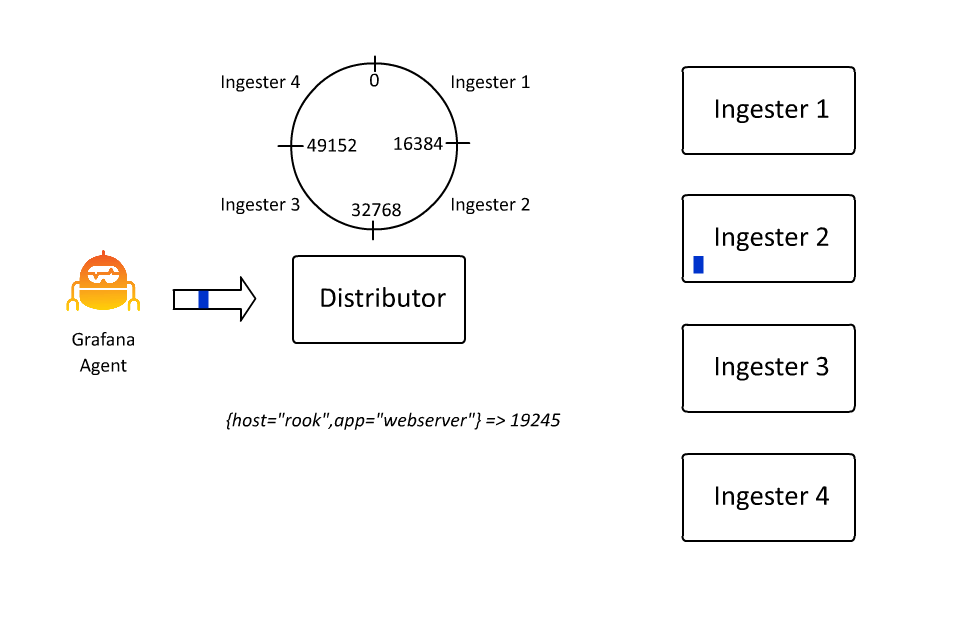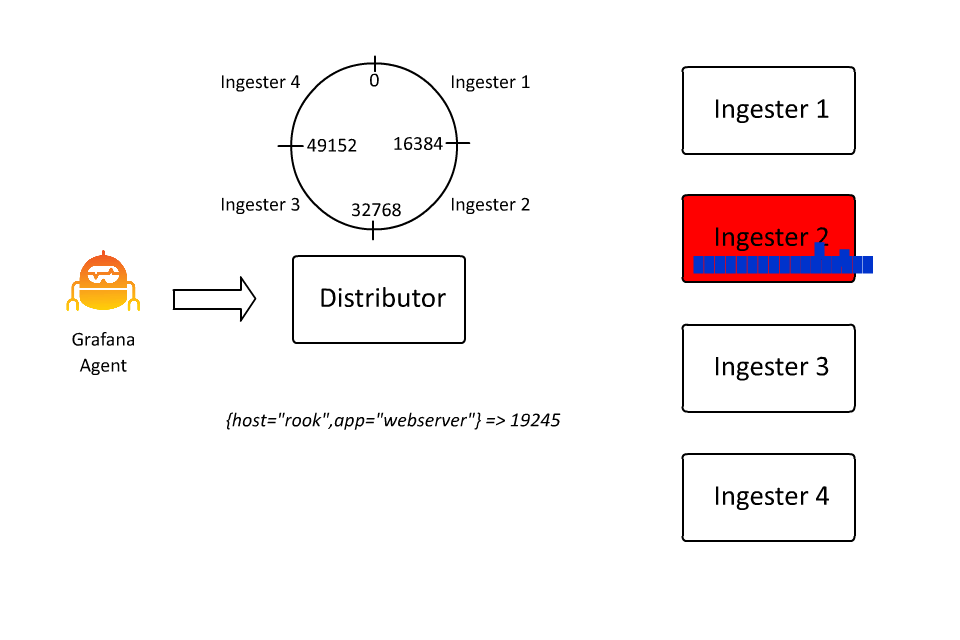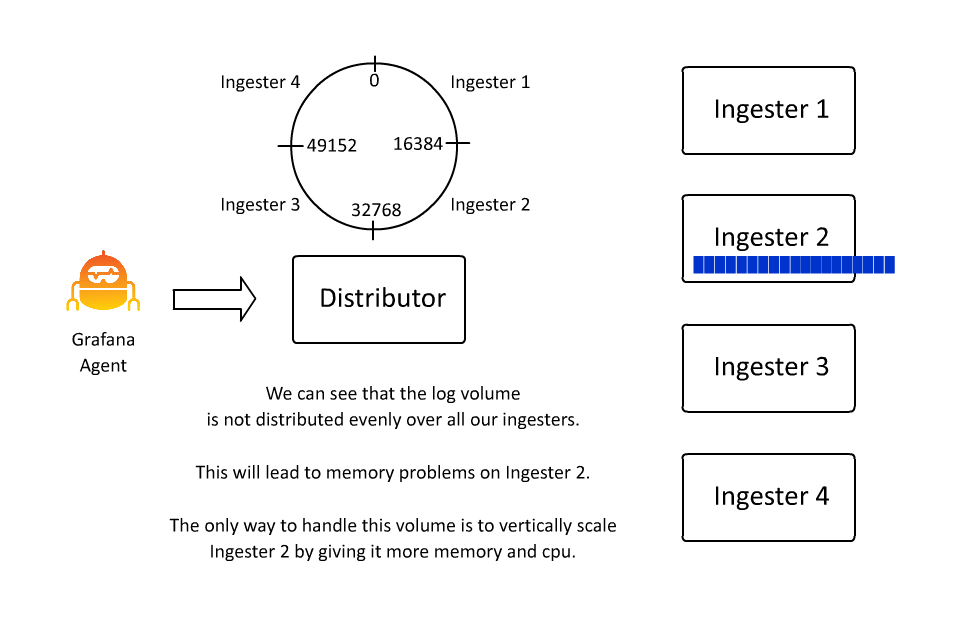
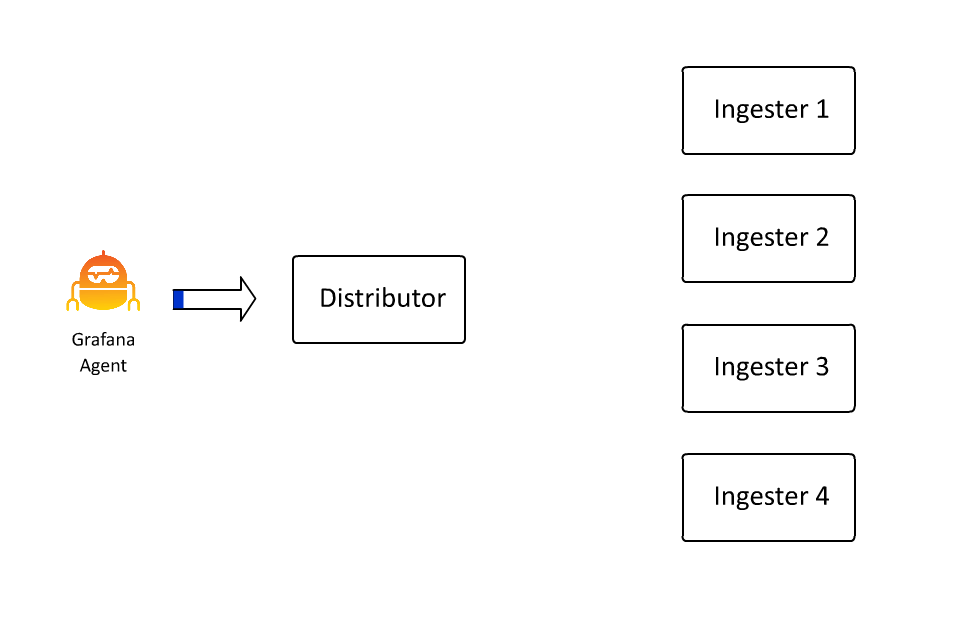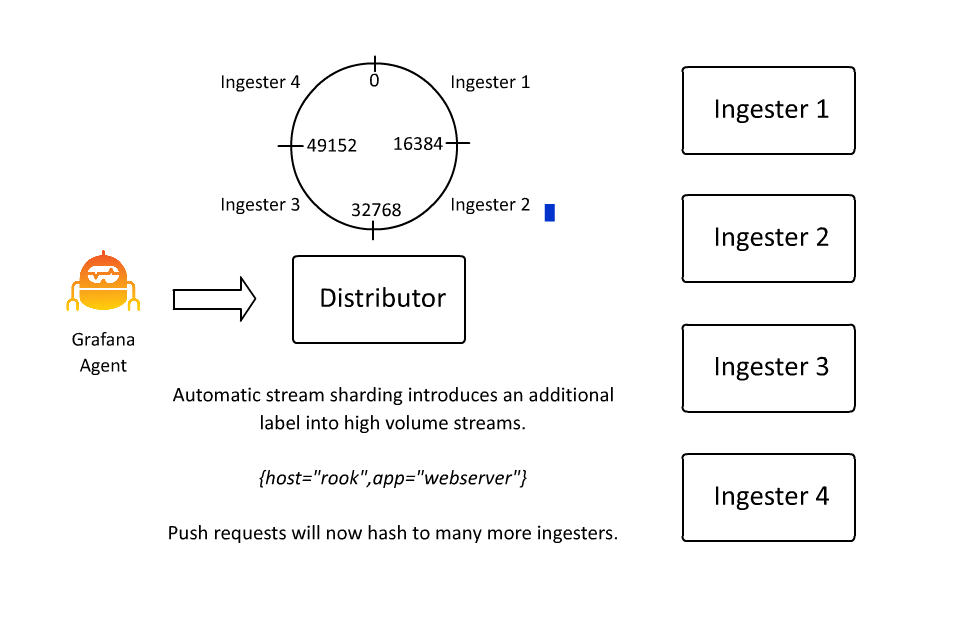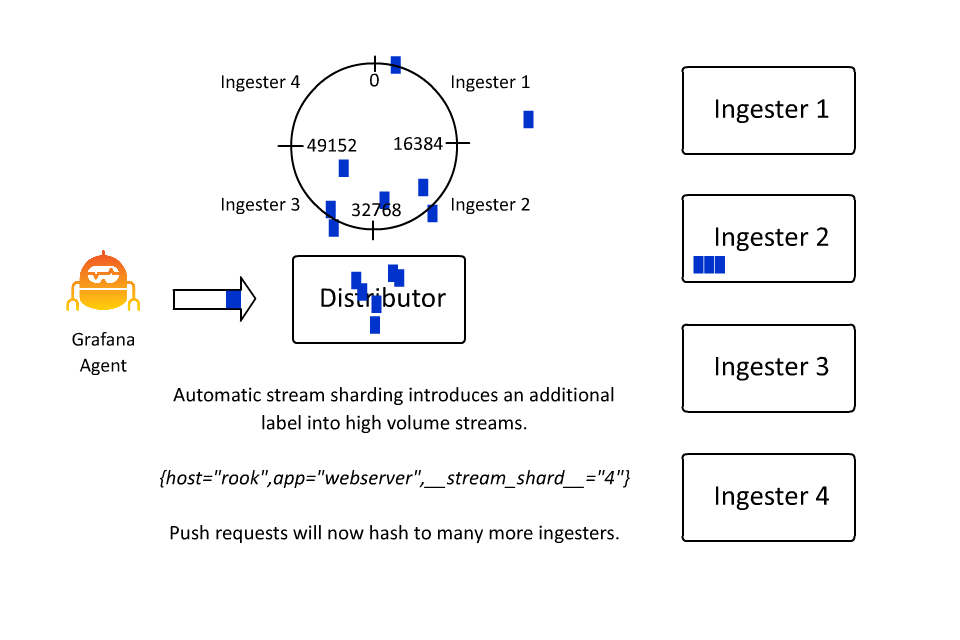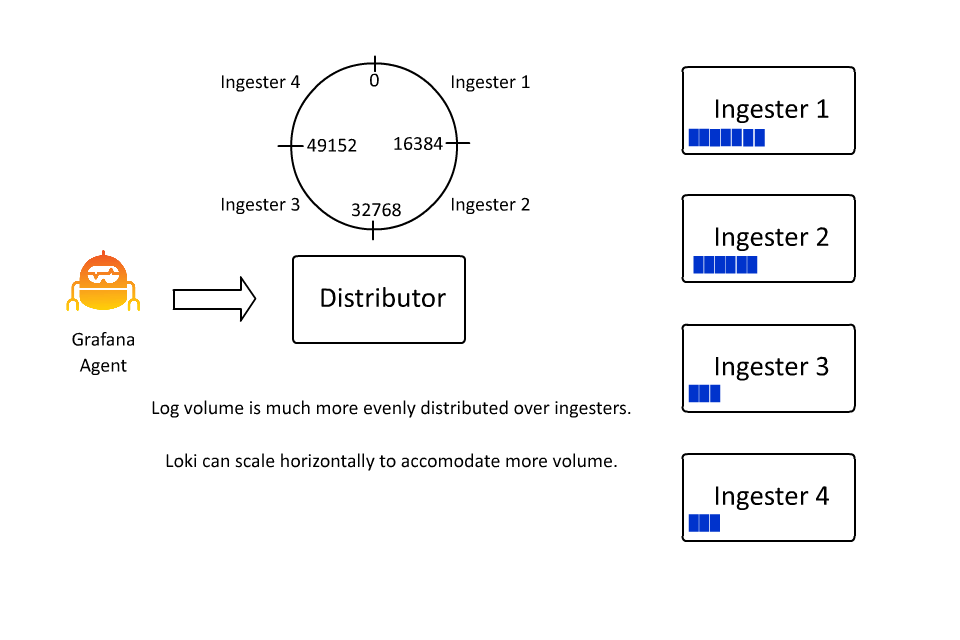
从操作的角度来看,这种情况并不理想,因此大约一年前,我们引入了 automatic stream sharding。这段代码会看到超过所需的最大数据流速率的数据流,并引入一个额外的标签 __stream_shard__,将该数据流自动分割成多个数据流。
随着数据流数量的增加,__stream_shard__ 标签会自动应用越来越多的值,将高流量数据流平均分配到更多的数据流中,以防止单个摄取器不堪重负。
pod 标签是什么?
Pod 是 Kubernetes 的一个概念,定义为 “可部署的最小计算单元”。对于某些 Kubernetes 工作负载来说,pod 的名称是短暂的。这可能会给 Loki 带来一个有趣的难题:在查询时,可能需要使用 pod 标签来对日志进行重要的消歧。然而,由于自动缩放或工作调度的原因,pod 可能会很短暂,从而导致大量的 cardinality,进而使 Loki 感到不悦。
从历史上看,我们会用两种方法之一来解决这个问题。如果总的 cardinality 能保持在每小时 100,000 个流以下,我们就会对 pod 标签进行索引。或者,如果高于这个数字,我们会使用 Promtail 中的 "pack" 阶段,将 cardinality 嵌入日志行中。这两种方法都不是很好的解决方案。
幸运的是,Loki 现已为这种情况提供了更好的解决方案: 结构化元数据 (在 2.9 中属于试验性质;将在 3.0 中成为 GA)。结构化元数据是一个可以在日志行而不是索引中存储键值对的地方。这样,我们就可以保留具有低 cardinality 标签的长生命期数据流,同时也有地方存储 cardinality 较高的数据,这对于在查询时进行筛选和分组是很有必要的。
我想在所有日志中搜索一个唯一 ID
我们注意到 Loki 用户的一个一贯行为:他们运行大量 "大海捞针" 式查询。具体地说,他们在大量时间段内寻找类似订单 ID 或 UID 的内容,并使用非常通用的标签匹配器。这样的查询可能如下 {env="prod"} |= “603e0dcf-9b24-4c37-8f0d-6d8ebe5c5c8a”
当 {env="prod"} 匹配数 TB 或数十 TB 的数据时,对 Loki 来说,执行这些类型的查询会很费劲。Loki 的并行性 使其能够以相当快的速度处理这些查询,大约每秒半 TB!不过,我也了解到,数据量可能很大,时间范围可能很长,即使这样也不够快。
因此,团队意识到这种使用情况非常普遍,决定扩展 Loki 以优化这种类型的搜索。也许有人会尝试把这些 ID 放到标签中,从而放到 Loki 的索引中,对吗?这样当然可以更快地找到包含 UID 的日志。但是,正如我们在上文所演示的那样,这样做有一些不好的副作用,其中之一就是会创建一个大得多的索引。事实上,这实质上将 Loki 的索引变成了 倒排索引,而倒排索引存在许多已知的扩展难题,与 Loki 的设计背道而驰。
因此,我们决定使用 布鲁姆过滤器 进行设计。Bloom 过滤器是一种节省空间的概率数据结构,非常适合这种应用。Bloom 过滤器可以告诉 Loki 它不需要查找的地方,而不是建立一个倒排索引,这种方式更节省空间,可扩展性也更强。我猜想我们将来会有关于 Bloom 过滤器的专门文章,您也可以观看 Grafana Labs 软件工程师 Vlad Diachenko 在 ObservabilityCON 上的精彩介绍:
目前正在构建和测试 Bloom 过滤器,并将在即将推出的 Loki 3.0 中提供。
关于标签你需要知道什么(TL;DR)
我知道我曾用 "简明扼要" 来形容这些博文。…

哈哈,我正在努力。不过,既然我们已经了解了标签的工作原理和变化,我想谈谈关于在 Loki 中使用标签的常见问题。与本系列 上一篇 中的做法类似,我将通过下面的示例总结一些最佳做法。
如何查询给定跟踪 ID 的所有日志?
切勿在标签值中放置高冗余度字段。Loki 并非为此而生,它会恨死你。将这些数据保留在日志行中,并在搜索中使用过滤表达式。使用标签匹配器尽可能缩小搜索空间。不过,在洛基 3.0 中,这种类型的搜索将在布鲁姆过滤器的帮助下得到大幅改进。
1 | |
但如果标签的 cardinality 很低呢?如果把日志级别提取到标签中,而我们的日志级别只有五个值,该怎么办?
多年来,"level" 标签一直是个有争议的标签,因为它会导致小数据流被分割得更小。不过,"level" 标签在查询时的实用性很高,而且还有助于在 Explore 日志量直方图中提供更好的体验。
因此,您可以提取日志行 level 并将其用作标签。
只有在其他情况下,你才应该从日志行中提取数据:
- 数据的 cardinality 较低,可能只有几十个值
- 值是长期存在的(例如,HTTP 路径的第一级:
/load,/save,/update) - 用户会在查询中使用这些标签,以提高查询性能。
如果其中有一条不正确,就不要做! 将这些数据留在日志行中,并使用过滤表达式进行搜索。
但是,如果我想写一个度量查询,并按 (路径) 添加一个总和,如果路径不是标签,我该怎么做?
为什么当我从 Lambda 或函数中发送日志时,除非包含请求 ID 或调用 ID,否则会出现 "out of order" 的错误?
我从以前的指南中摘录了这两个问题,并将它们合并在一起,因为在这两种情况下,Loki 都有了改进,使这些问题变得过时了。
Loki 2.0 引入了一种查询语言,能够在查询时将任何内容提取到标签中,而 Loki 2.4 则允许接收不按顺序排列的日志。
摘要
如果你没有从这篇博客中得到任何其他东西,那就请记住这一点: 虽然 Loki 和 Prometheus 共享标签的概念,但它们的应用却截然不同。如果在 Loki 中正确使用标签,就不会出现任何 cardinality 问题。
因此,重申一下,好的标签应具备以下品质:
- 描述基础设施:区域、集群、服务器、应用程序、命名空间、环境
- 具有长期有效的值。标签值应永久生成日志,或至少持续数小时
- 查询直观
只有当查询模式能直接受益于少量额外的标签值对时,才能从日志行中提取内容,而且标签应满足以下条件:
-
Cardinality 低,可能只有几十或几百个值
- 一般情况下,您应尽量将 Loki 中的任何单个租户的活动数据流控制在 10 万个以下,24 小时内的数据流控制在一百万个以下。 这些值适用于每天发送量超过 10 TB 的大型租户。如果你的租户小 10 倍,那么你的标签数量可能至少要少 10 倍。
-
这些值是长期存在的(例如,HTTP 路径的第一级:
/load、/save、/update)。- 不要在标签中提取跟踪 ID 或订单 ID 等短暂值,这些值应该是静态的,而不是动态的。
-
用户会在查询中使用这些标签来提高查询性能。
- 如果实际上没有人使用这些标签,就不要增加索引的大小和分割日志流。如果没有人使用它们,你就会把事情搞得更糟。
感谢您加入我的博客之旅,希望这一系列文章对您的洛基之旅有所帮助。请在下周继续阅读有关调整 Loki 查询性能的简明指南。
