Grafana 系列文章(九):开源云原生日志解决方案 Loki 简介
本文最后更新于:2024年7月25日 下午
简介
Grafana Labs 简介
Grafana 是用于时序数据的事实上的仪表盘解决方案。它支持近百个数据源。
Grafana Labs 想从一个仪表盘解决方案转变成一个可观察性 (observability) 平台,成为你需要对系统进行调试时的首选之地。
完整的可观察性
可观察性。关于这意味着什么,有很多的定义。可观察性就是对你的系统以及它们的行为和表现的可见性。典型的是这种模式,即可观察性可以分成三个部分(或支柱):指标 (Metrics)、日志 (Logs) 和跟踪 (Traces);每个部分都相互补充,帮助你快速找出问题所在。
下面是在 Grafana Labs 博客和演讲中反复出现的一张图:
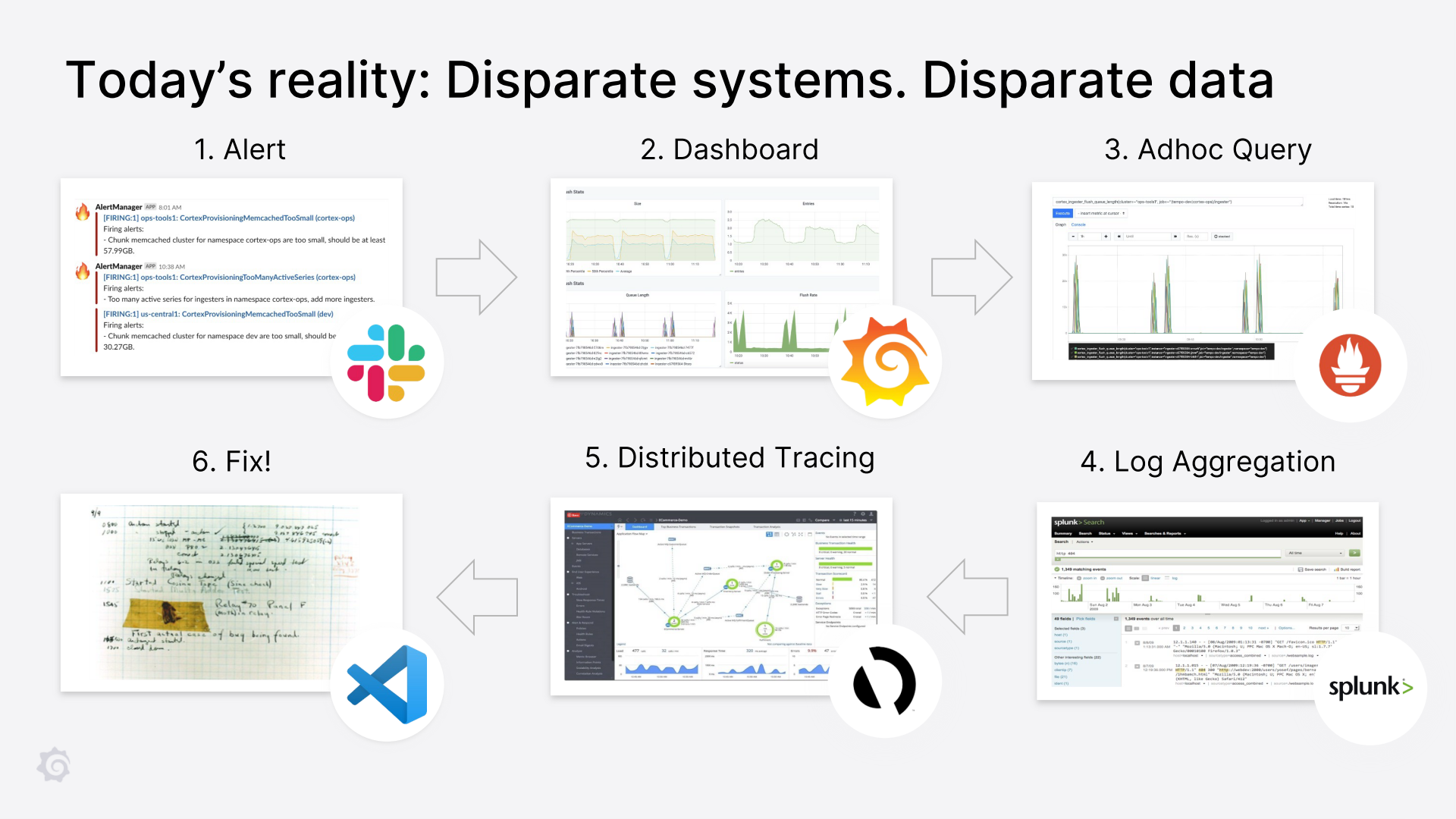
Slack 向我发出警告,说有问题,我就打开 Grafana 上服务的相关仪表盘。如果我发现某个面板或图表有异常,我会在 Prometheus 的用户界面中打开查询,进行更深入的研究。例如,如果我发现其中一个服务抛出了 500 个错误,我会尝试找出是否是某个特定的处理程序 / 路由抛出了这个错误,或者是否所有的实例都抛出了这个错误,等等。
接下来,一旦我有了一个模糊的心理模型,知道什么地方出了问题,我就会看一下日志(比如在 splunk 上)。在 Loki 之前,我习惯于使用 kubectl 来获取相关的日志,看看错误是什么,以及我是否可以做些什么。这对错误来说很有效,但有时我会因为高延迟而放弃。之后,我从 traces (比如 AppD) 中得到更多的信息,关于什么是慢的,哪个方法 / 操作 / 功能是慢的。或者使用 Jaeger 来获得追踪信息。
虽然它们并不总是直接告诉我哪里出了问题,但它们通常让我足够近距离地查看代码并找出哪里出了问题。然后,我可以扩展服务(如果服务超载)或部署修复。
Loki 项目背景
Prometheus 工作得很好,Jaeger 也渐入佳境,而 kubectl 也很不错。标签 (label) 模型很强大,足以让我找到出错服务的根源。如果我发现 ingester 服务在出错,我会做:kubectl --namespace prod logs -l name=ingester | grep XXX,以获得相关的日志,并通过它们进行 grep。
如果我发现某个特定的实例出错了,或者我想跟踪某个服务的日志,我必须使用单独的 pod 来跟踪,因为 kubectl 不允许你根据标签选择器来跟踪。这并不理想,但对于大多数的使用情况来说是可行的。
只要 pod 没有崩溃或者没有被替换,这就可以了。如果 pod 或节点被终止了,日志就会永远丢失。另外,kubectl 只存储最近的日志,所以当我们想要前一天或更早的日志时,我们是盲目的。此外,不得不从 Grafana 跳到 CLI 再跳回来的做法并不理想。我们需要一个能减少上下文切换的解决方案,而我们探索的许多解决方案都非常昂贵,或者不能很好地扩展。
这是意料之中的事,因为它们比 select + grep 做得更多,而这正是我们所需要的。在看了现有的解决方案后,Grafana Labs 决定建立自己的。
Loki
由于对任何开源的解决方案都不满意,Grafana Labs 开始与人交谈,发现很多人都有同样的问题。事实上,Grafana Labs 已经意识到,即使在今天,很多开发人员仍然在 SSH 和 grep/tail 机器上的日志。他们所使用的解决方案要么太贵,要么不够稳定。事实上,人们被要求减少日志,Grafana Labs 认为这是一种反模式的日志。Grafana Labs 认为可以建立一些 Grafana Labs 内部和更广泛的开源社区可以使用的东西。Grafana Labs 有一个主要目标:
- 保持简单。只支持 grep!
Grafana Labs 还瞄准了其他目标:
- 日志应该是便宜的。不应要求任何人少记录日志。
- 易于操作和扩展
- 指标 (Metrics)、日志 (Logs)(以及后来的追踪 (traces))需要一起工作
最后一点很重要。Grafana Labs 已经从 Prometheus 收集了指标的元数据,所以想利用这些元数据进行日志关联。例如,Prometheus 用 namespace、service name、实例 IP 等来标记每个指标。当收到警报时,使用元数据来找出寻找日志的位置。如果设法用同样的元数据来标记日志,我们就可以在度量和日志之间无缝切换。你可以在 这里 看到 Grafana Labs 写的内部设计文档。下面是 Loki 的演示视频链接:
架构
根据 Grafana Labs 建立和运行 Cortex 的经验–作为服务运行的 Prometheus 的水平可扩展的分布式版本–想出了以下架构:
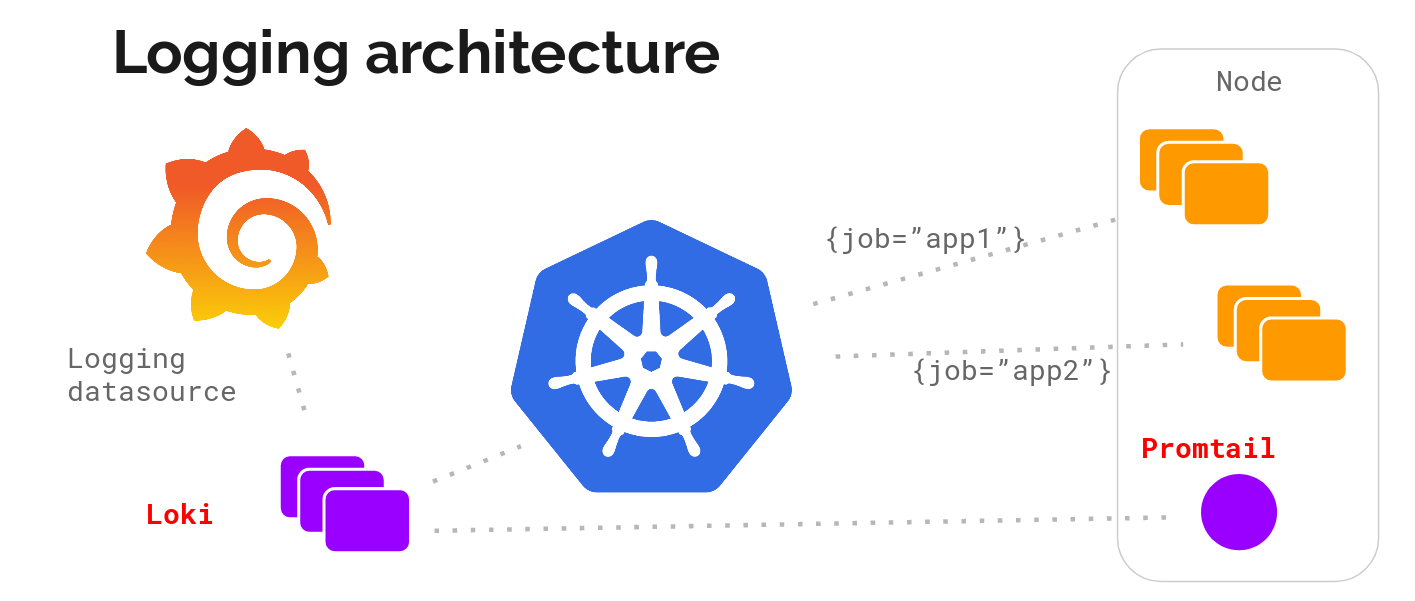
指标和日志之间的元数据匹配对我们来说至关重要,Grafana Labs 最初决定只针对 Kubernetes。想法是在每个节点上运行一个日志收集代理,用它来收集日志,与 kubernetes 的 API 对话,为日志找出正确的元数据,并将它们发送到一个中央服务,可以用它来显示在 Grafana 内收集的日志。
该代理支持与 Prometheus 相同的配置(relabelling rules),以确保元数据的匹配。我们称这个代理为 promtail。
深入 Loki —— 可扩展的日志收集引擎:
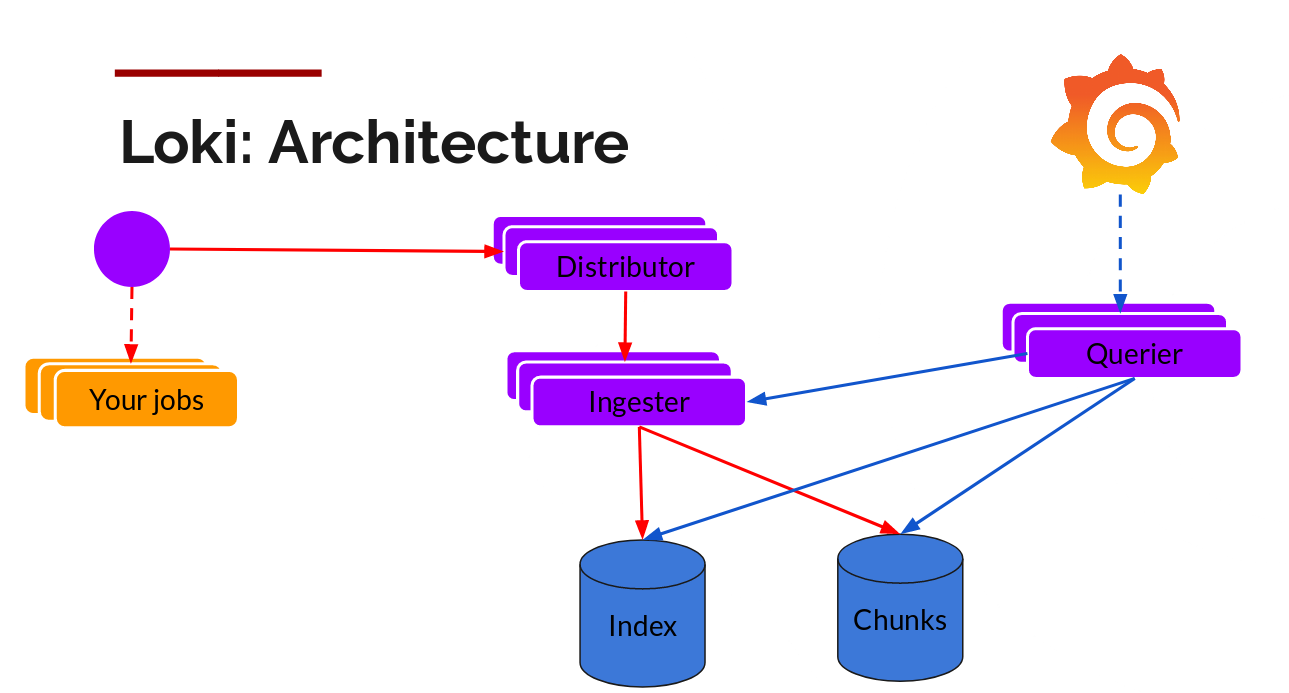
写入路径和读取路径(查询)是相互脱钩的,分开说明:
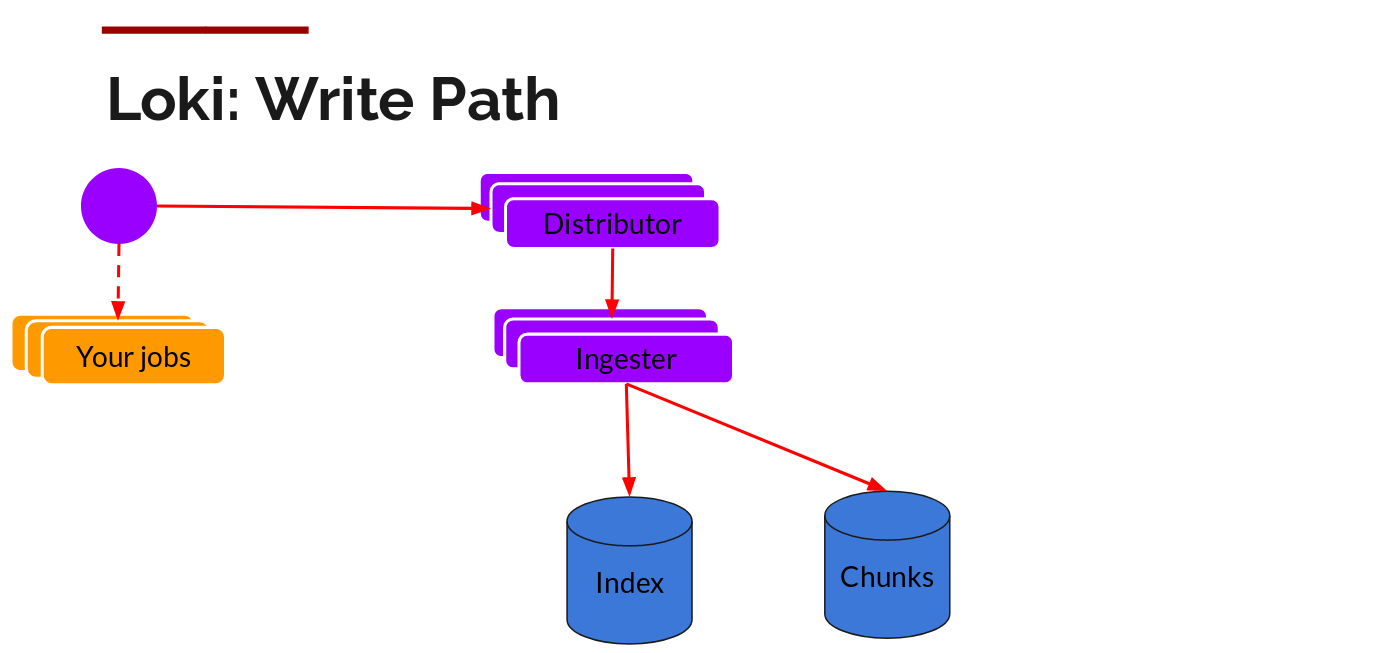
Distributor(分发器)
一旦 promtail 收集并发送日志到 Loki,Distributor 是第一个接收日志的组件。现在,Loki 可能每秒收到数百万条写,我们不想在它们进来时就把它们写到数据库中。那会搞宕任何数据库。需要在数据进入时对其进行批处理和压缩。
Grafana Labs 通过构建压缩的数据块 (chunks),通过 gzip 压缩日志来实现这一点。ingester(采集器) 组件是一个有状态组件,负责构建块,然后再刷新块。Loki 有多个 ingester,属于每个流的日志应该总是在同一个 ingester 中结束,因为所有相关条目都在同一个块中结束。通过构建一个 ingester 环 (ring) 并使用一致性哈希来做到这一点。当有条目进入时,分 Distributor 对日志的标签进行哈希处理,然后根据哈希值查找将条目发送到哪个 ingester。
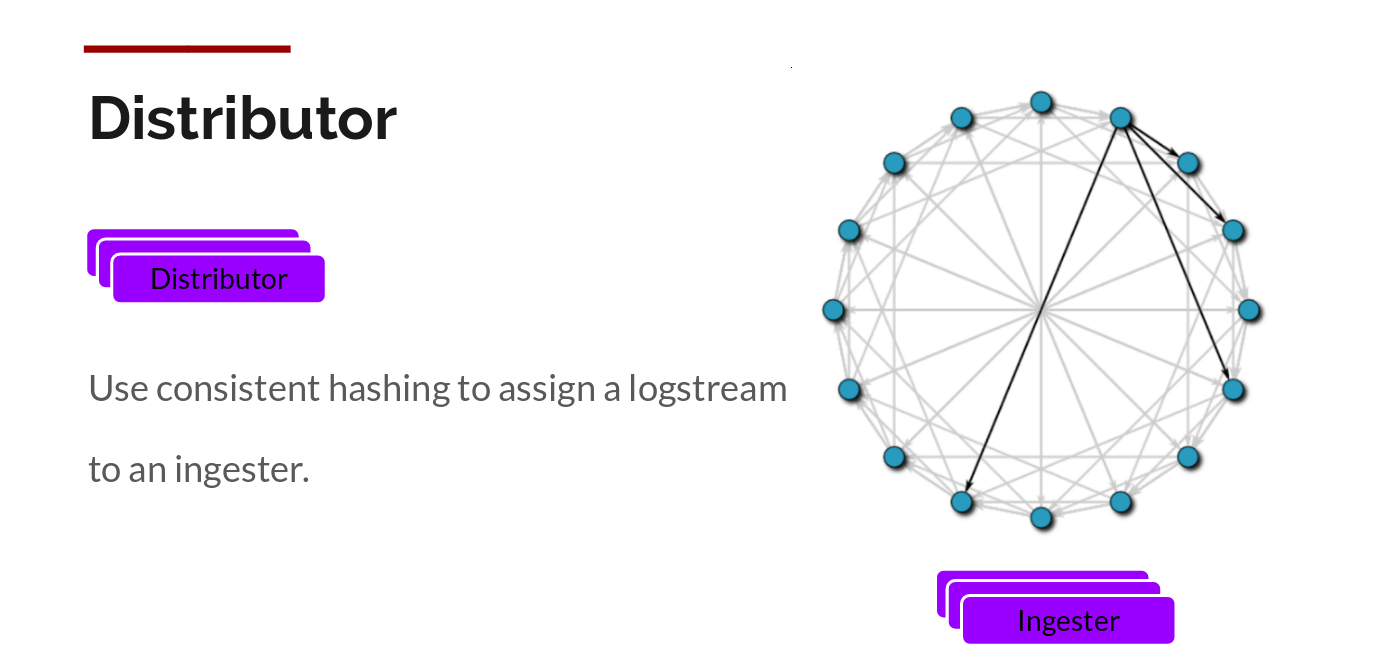
此外,为了实现冗余和弹性,Loki 将其复制了 n 次(默认为 3 次)。
Ingester(采集器)
现在,Ingester 将接收条目并开始构建块。
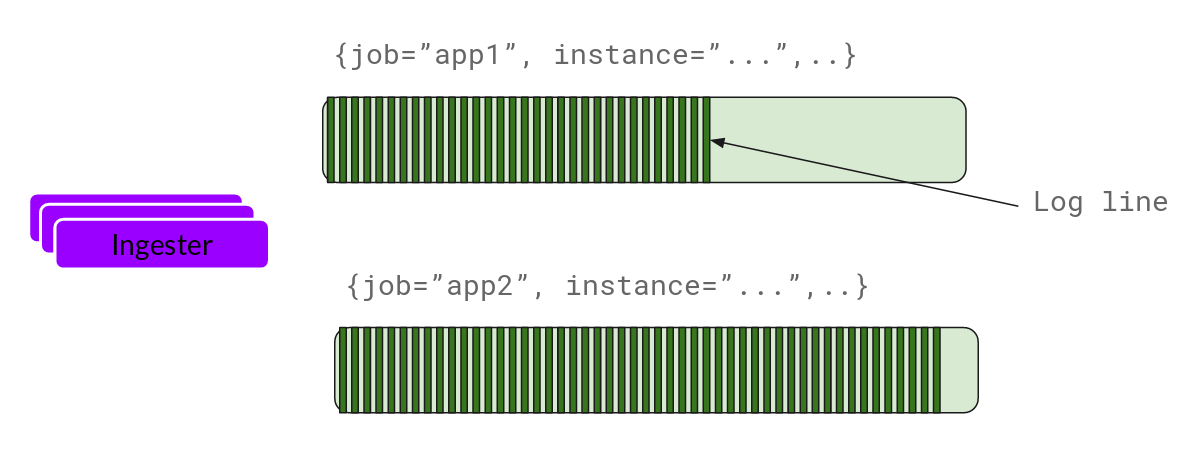
这基本上是对日志进行 gzip 处理并追加。一旦块 "填满" 了,我们就把它刷到数据库中。我们为块(ObjectStorage)和索引使用不同的数据库,因为它们存储的数据类型是不同的。

刷完一个块后,Ingester 会创建一个新的空块,并将新条目添加到该块中。
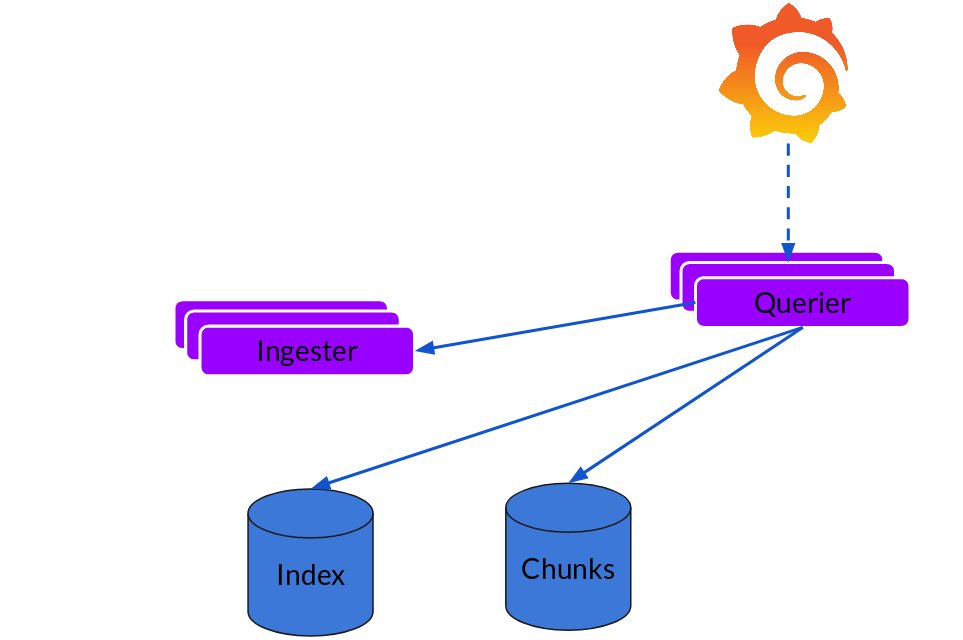
Querier(查询器)
读取路径非常简单,由 Querier 来完成大部分繁重的工作。给定一个时间范围和标签选择器,它查看索引以找出匹配的块,并通过它们进行搜索,给你结果。它还与 ingesters 对话,以获得尚未被刷到库中的最新数据。
请注意,在 2019 年版本中,对于每个查询,一个 Ingester 为你搜索所有相关的日志。Grafana Labs 已经在 Cortex 中使用前端实现了查询并行化,同样的方法可以扩展到 Loki,以提供分布式的 grep,这将使大型查询变得足够迅速。
可伸缩性
- Loki 把块的数据放到对象存储中,这样就可以扩展了。
- Loki 把索引放到 Cassandra/Bigtable/DynamoDB 或 Loki 内置的 index db 中,这也是可以扩展的。
- Distributors 和 Queriers 是无状态组件,可以横向扩展。
说到 ingester,它是一个有状态的组件,但 Loki 已经将完整的分片和重新分片的生命周期纳入其中。当 rollout 工作完成后,或者当 ingester 被扩大或缩小时,环形拓扑结构会发生变化,ingester 会重新分配它们的块,以匹配新的拓扑结构。这主要是取自 Cortex 的代码,它已经在生产中运行了 5 年多。
总结
Loki: like Prometheus, but for logs.
Loki 是一个水平可扩展、高可用、多租户的日志聚合系统,其灵感来自于 Prometheus。它被设计成非常具有成本效益和易于操作。它不对日志的内容进行索引,而是为每个日志流提供一组标签。
