「读书笔记」《大规模分布式存储系统:原理解析与架构实战》:四
本文最后更新于:2024年7月25日 下午
🔖 图书:
《大规模分布式存储系统:原理解析与架构实战》
杨传辉著
4 分布式文件系统
4.1 GFS
4.1.1 系统架构
组件:
- GFS Master(主控服务器)
- GFS ChunkServer (CS 数据块服务器)
- GFS 客户端
GFS 文件被分为固定大小的数据库(chunk),主服务器在创建时分配一个 64 位全局唯一的 chunk 句柄。
chunk 在不同的机器中复制多份,默认为 3 份。
主控服务器中维护了系统的元数据,包括文件及 chunk 命名空间、文件到 chunk 之间的映射、chunk 位置信息。也负责整个系统的全局控制,如 chunk 租约管理、垃圾回收无用 chunk、chunk 复制等。主控服务器会定期与 CS 通过心跳的方式交换信息。
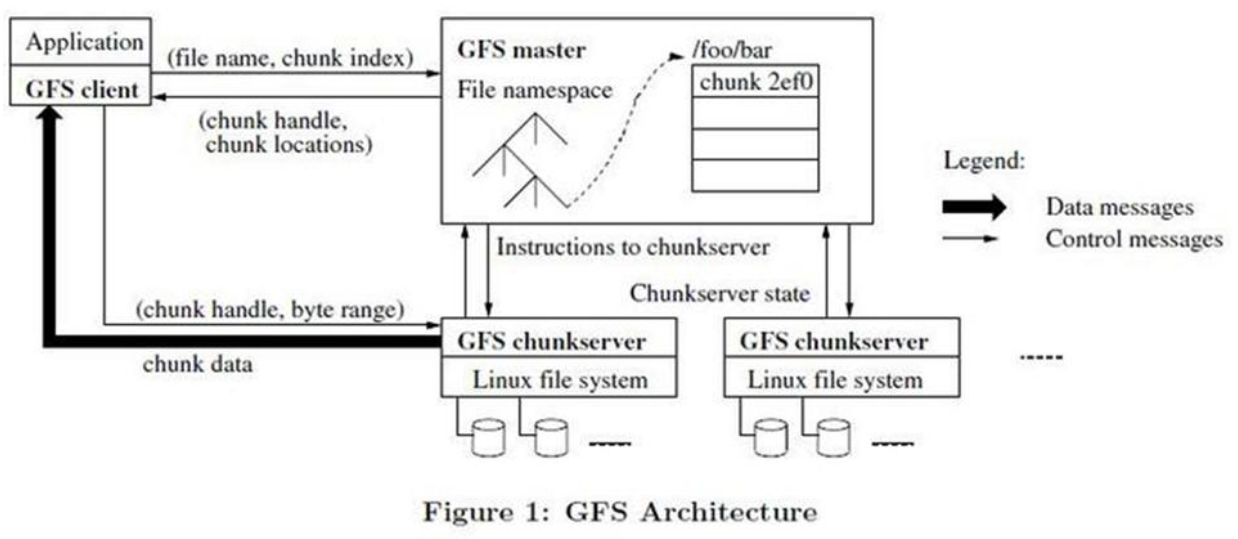
客户端是 GFS 提供给应用程序的访问接口,它是一组专用接口,不遵循 POSIX 规范,以库文件的形式提供。客户端访问主控节点,获取与之进行交互的 CS 信息,然后直接访问这些 CS,完成数据存取工作。
❗ 注意:
GFS 中的客户端不缓存文件数据,只缓存主控服务器中获取的元数据。
4.1.2 关键问题
租约机制
GFS 数据追加以记录为单位,每个记录大小为几十 KB 到几 MB 不等,如果每次记录追加都需要请求 Master,Master 会成为瓶颈,因此,GFS 系统中通过租约(lease)机制将 chunk 写操作授权给 ChunkServer。拥有租约授权的为 主 ChunkServer,其他副本所在的 ChunkServer 称为备 ChunkServer。租约授权针对单个 chunk,在租约有效期内,对该 chunk 的写操作都由 主 ChunkServer 负责,从而减轻 Master 的负载。一般来说,租约的有效期比较长,比如 60s,只要没异常,主 ChunkServer 可以不断向 Master 请求延长租约的有效期直到整个 chunk 写满。
GFS 通过对每个 chunk 维护一个版本号来解决,每次给 chunk 进行租约授权或主 ChunkServer 重新延长租约有效期,Master 会将 chunk 的版本号加 1. 如果过程中某个 A chunk 的副本 A2 下线,A2 的版本号会低,从而将 A2 标记为可删除的 chunk,Master 的垃圾回收任务会定时检查,并通知 ChunkServer 将 A2 回收掉。
一致性模型
GFS 主要是为了追加(append)而不是改写(overwrite)而设计的。
追加模型
容错机制
Master 容错
通过操作日志加 checkpoint 的方式进行,并且有一台 「Shadow Master」实时热备。
Master 上保存了三种元数据信息:
- 命名空间(NameSpace),也就是整个文件系统的目录结构以及 chunk 基本信息;
- 文件到 chunk 之间的映射
- chunk 副本的位置信息,每个 chunk 通常有 3 个副本
Master 操作总是先记录操作日志,后修改内存。
远程的实时热备将实时接收 Master 发送的操作日志并在内存中回放这些元数据操作。如果 Master 宕机,还可以秒级切换到实时备机继续提供服务。
Master 需要持久化 命名空间 和 文件到 chunk 之间的映射;chunk 副本的位置信息可以不持久化,因为 chunkserver 维护了这些信息。
ChunkServer 容错
多副本。对于每个 chunk,必须将所有的副本全部写入成功,才视为成功写入。
ChunkServer 会对存储的数据维持校验和。
GFS 以 64MB 为 chunk 大小来划分文件,每个 chunk 又以 block 为单位进行划分,Block 大小为 64KB,每个 Block 对应一个 32 位的校验和。当读取一个 chunk 副本时,ChunkServer 会将读取的数据和校验和进行比较,如果不匹配,就会返回错误,客户端将选择其他 ChunkServer 上的副本。
4.1.3 Master 设计
Master 内存占用
每个 chunk 的元数据小于 64 字节。那么 1PB 数据的 chunk 元数据大小不超过 1PB * 3 / 64MB * 64 = 3GB
Master 还对命名空间进行了压缩,每个文件在文件命名空间的元数据也不超过 64 字节。因此 Master 内存容量不会成为 GFS 的系统瓶颈。
负载均衡
创建副本有 3 种情况:
- chunk 创建
- chunk 复制(re-replication)
- 负载均衡(rebalancing)
如何选择 chunk 副本的初始位置:
- 新副本所在的 ChunkServer 的磁盘利用率低于平均水平
- 限制每个 ChunkServer 「最近」创建的数量
- 每个 chunk 的所有副本不能在同一个机架。
垃圾回收
延迟删除的机制。在元数据中将文件改名为一个隐藏的名字,并且包含一个删除时间戳(默认 3 天)。
垃圾回收一般在服务低峰期执行,如凌晨 1:00.
快照
使用标准的写时复制机制生成快照,「快照」只是增加 GFS 中 chunk 的引用计数,表示这个 chunk 被快照文件引用了,等到客户端修改 这个 chunk 时,才需要在 ChunkServer 中拷贝 chunk 的数据生成新的 chunk,后续的修改操作落到新生成的 chunk 上。
做快照,首先需要停止这个文件的写服务(通过租约机制收回),接着增加这个文件的所有 chunk 的引用计数,以后修改这些 chunk 时会拷贝生成新的 chunk。
4.1.4 ChunkServer 设计
保证 ChunkServer 尽可能均匀地分布在不同的磁盘中。删除 chunk 时可以只将对应的 chunk 文件移动到每个磁盘的回收站,以后新建 chunk 可以重用。
4.1.5 讨论
典型优势:大大降低成本,由于基础设施成本低,Gmail 服务能够免费给用户提供更大的容量。
4.2 Taobao File System
2007 年之前淘宝图片存储系统使用 NetApp 存储系统。
TFS:Blob 存储系统。
TFS 架构设计考虑以下 2 个问题:
- Metadata 信息存储。图片数量巨大,单机放不下所有的元数据信息。
- 减少图片读取的 IO 次数。
设计思路:多个逻辑图片文件共享一个物理文件
4.2.1 系统架构
TFS 不维护文件目录树,每个小文件使用一个 64 位的编号表示。
一个 TFS 集群由:
- 2 个 NameServer 节点(一主一备)
- 多个 DataServer 节点
NameServer 通过 心跳对 DataServer 进行检测。
每个 DataServer 会运行多个 dsp 进程,一个 dsp 对应一个挂载点,这个挂载点一般对应一个独立磁盘,从而管理多块磁盘。

在 TFS 中,将大量的小文件(实际数据文件)合并成一个大文件,这个大文件称为块(Block),每个 Block 拥有集群内唯一的编号(块 ID),通过块 ID,文件编号 可以唯一确定一个文件。Block 数据大小一般为 64 MB,默认 3 份。
追加流程
TFS 是写少读多的,那么每次写操作都经过 NameNode 也不会有问题。
另外,TFS 不需要支持 GFS 的多客户端并发追加操作,同一时刻每个 Block 只能有一个写操作,多个客户端的写操作会被串行化。
NameServer
功能:
- Block 管理,包括创建、删除、复制、重新均衡;
- DataServer 管理,包括心跳、DataServer 加入及退出;
- 管理 Block 与所在 DataServer 之间的映射关系
与 GFS 相比,TFS NameServer:
- 不需要保存文件目录树信息;
- 不需要维护文件与 Block 之间的映射关系
4.2.2 讨论
- 图片去重:MD5 或 SHA1
- 图片更新于删除
4.3 Fackbook Haystack
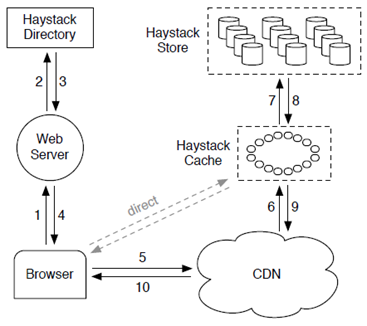
- 目录(Directory)
- 存储(Store)
- 缓存(Cache)
