案例 2: 某寿险公司核心系统 GC 开销超限问题分析
本文最后更新于:2025年2月22日 下午
概述
某寿险公司的核心系统是运行在 x86 物理服务器上的, x86 物理服务器的性能都挺好,但是系统的性能却不尽如人意。而且之前某寿险公司的核心系统出过几次性能上的问题,但是我们总是找不到根本原因。每次都是重启完了事,也不清楚性能问题究竟对系统造成了什么样的影响。
装上 Dynatrace 之后,立马就有关于某寿险公司核心系统的性能告警,告警是关于 GC 对系统性能造成较大影响 (即 JVM 的 GC 开销超过限制),我们这才知道问题的严重性,也知道了从何下手。之后我们定位到导致系统问题的根源,一个是加载的一个用来监控应用各项参数的 javamelody 的 jar 包,另一个是因为 system.gc() 频繁地调用 fullgc,导致系统 “stop the world” 时间过长。
分析过程
告警
某寿险公司核心系统安装上 Dynatrace 之后,立马出现如下的告警邮件:
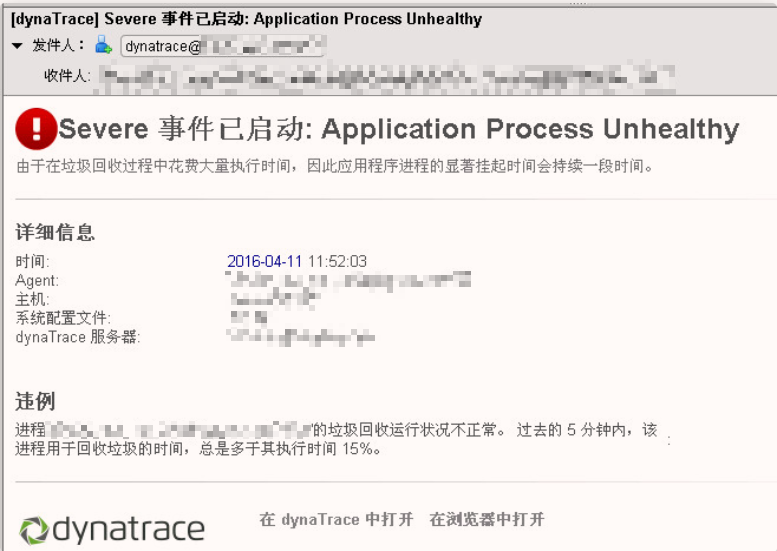
可以清楚的看到,告警邮件上已经明确的写出了原因,并指出对性能的影响:
原因:进程 XXXX_wls_hx_135a@appserver135:0 的垃圾回收运行状况不正常。 由于在垃圾回收过程中花费大量执行时间,因此应用程序进程的显著挂起时间会持续一段时间。
影响: 过去的 5 分钟内,该进程用于回收垃圾的时间,总是多于其执行时间 15%。
多于其执行时间 15%!是的,直到看到这个告警,我们才意识到性能问题居然这么严重,GC 所花费的时间,在某段时间内已经超过总的执行时间的 15%,而且此告警很频繁。具体如下:
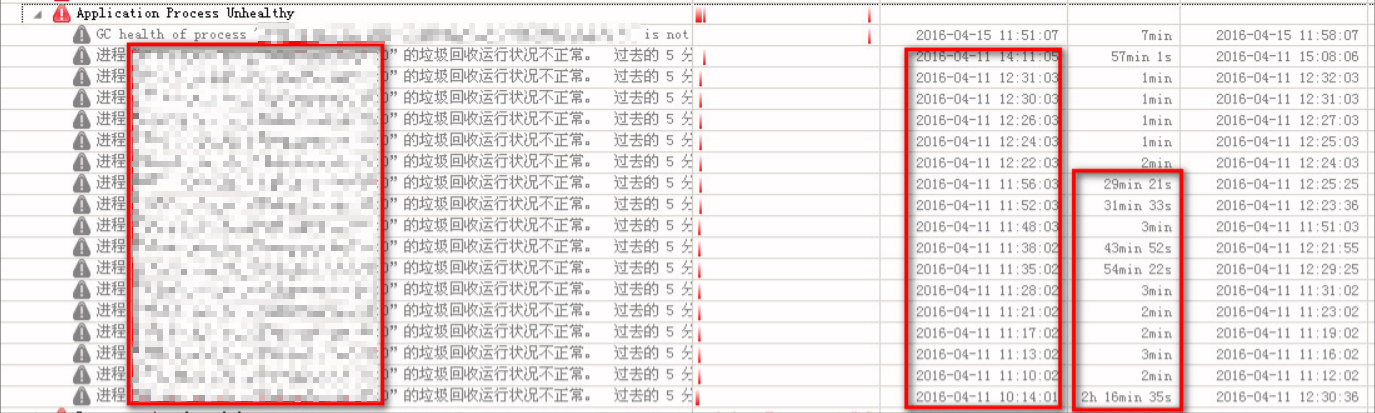
可以从上图看出,核心系统的大部分机器都出现了性能问题,并且很频繁,另外有时甚至在长达 1、2 个小时内,GC 时间占用执行时间超过 15%!这是很严重的性能问题。而该问题直到我们使用了 Dynatrace 才首次意识到。
GC 问题优化
针对该问题,为了进一步分析,我们使用了 Dynatrace 自带的仪表图–应用程序进程图表。具体如下:
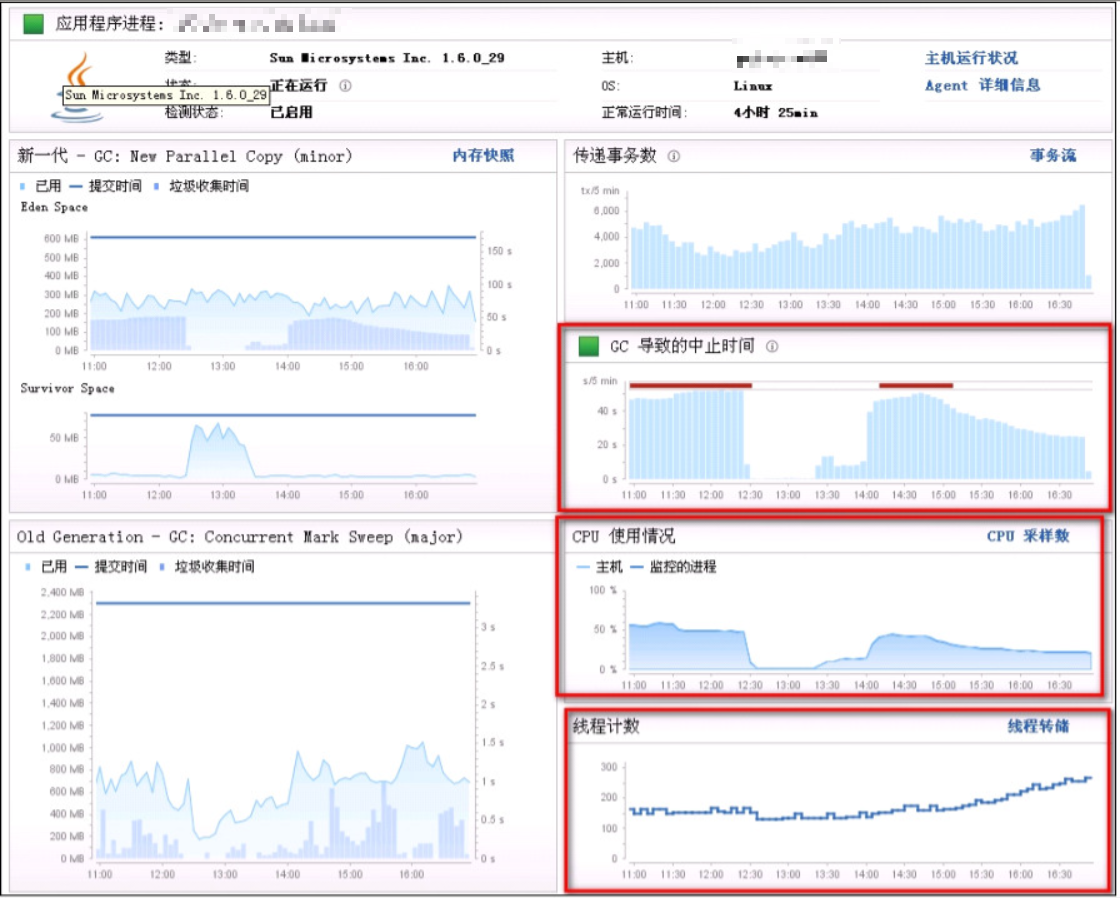
从这儿可以看出,告警的时候 major gc 垃圾收集时间较长,而 Dynatrace 的 major gc 就是指会导致 “stop the world” 的 GC。
接下来我们分析了对应的 GC 日志,发现日志中存在大量的 system.gc()(就是程序里手动调用该方法),并且每次调用都是执行 full gc。关于 SystemGC 触发 full gc 的解释,我们查到的原因如下:
如果应用使用到 NIO 框架、DirectByteBuffer 或者 MappedByteBuffer 等功能时,上述情况产生的内存是堆外内存,SystemGC 就需要 Full GC 来回收
之后查看资料,发现一种具体的改进方法,具体如下:
加入参数
-XX:+ExplicitGCInvokesConcurrent,该参数并不会禁用 SystemGC,SystemGC 还是会被触发,只是加上该参数后,会使得 system gc 时执行 CMS GC,效率会提高,减少因为 Full GC 引起的 STW 时间。
之后我们在其中一台上添加了该参数,添加之后与其他没有添加的做对比,利用 dynatrace 的自定义仪表板的功能,直接抓取 “Suspension Time"(每个时间间隔中 GC 导致的挂起时间) 这一参数做对比画出曲线图。发现加了后 GC 导致的暂停时间大幅下降!由于比较早,该图找不到了,附上一张使用另一个小工具分析的结论:
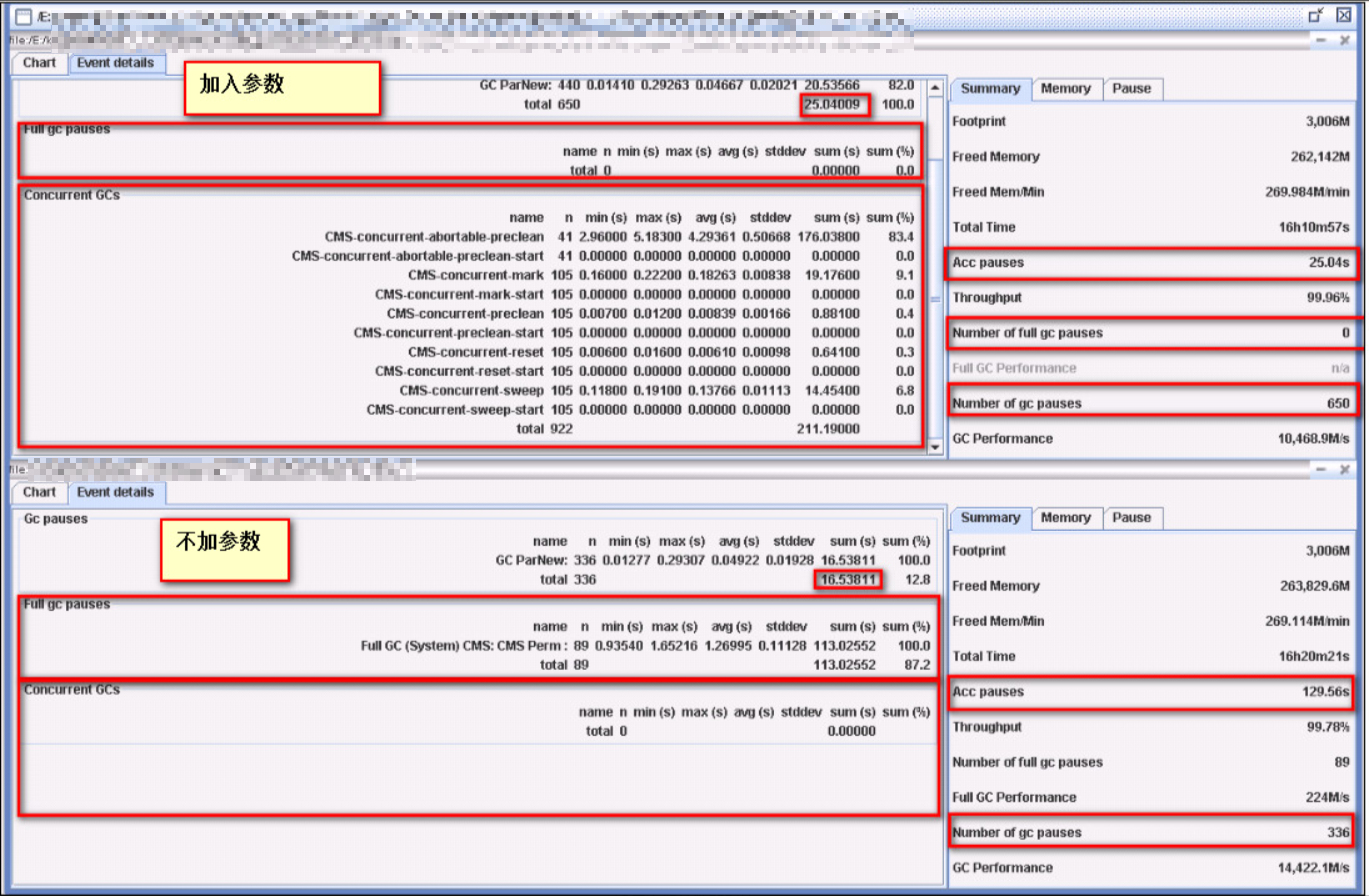
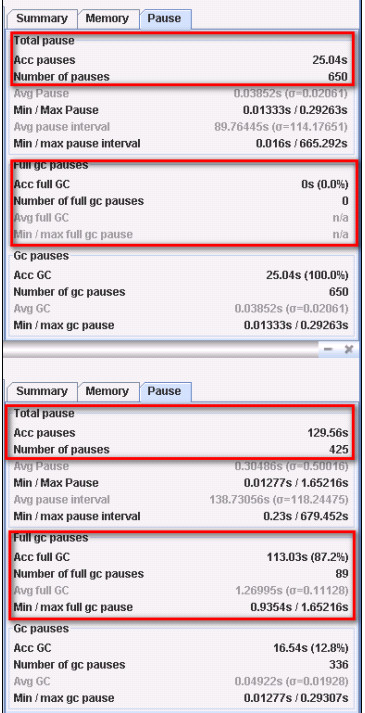
可以看到,不加该参数,GC 导致的暂停时间有 129.56s;加上该参数后,GC 导致的暂停时间只有 25.04s,是原来暂停时间的 1/5 - 1/6。且加了该参数后,fullGC 从 89 次降到了 0 次。
简而言之:加了之后 GC “stop the world” 时间降低了 100 多秒,full gc 次数为 0。
确认加上该参数可以改善 gc 性能后,我们在核心系统的所有 jvm 里都添加了该参数。加入后,除了其中一台机器还会告警,其他机器运行正常。而那台告警的机器,我们发现还有其他的问题。
javamelody
其中一台,即使加入了上边提到的参数,gc 的性能还是有问题。具体如下图:
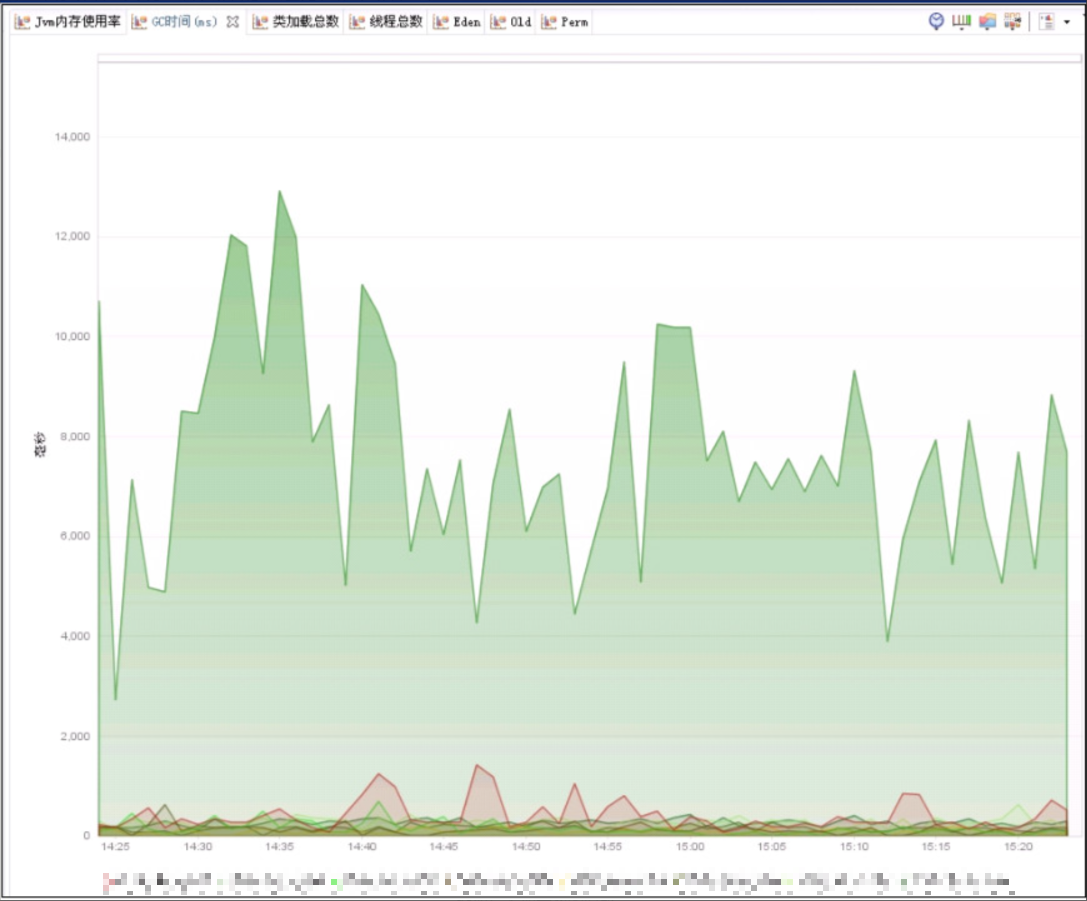
可以看到,GC 暂停时间,其他 jvm 都是位于 10ms 左右的数量级,而另一台则是 6000ms 左右的数量级!这对应用造成了较大的影响,具体可以通过 dynatrace 的下图看出:
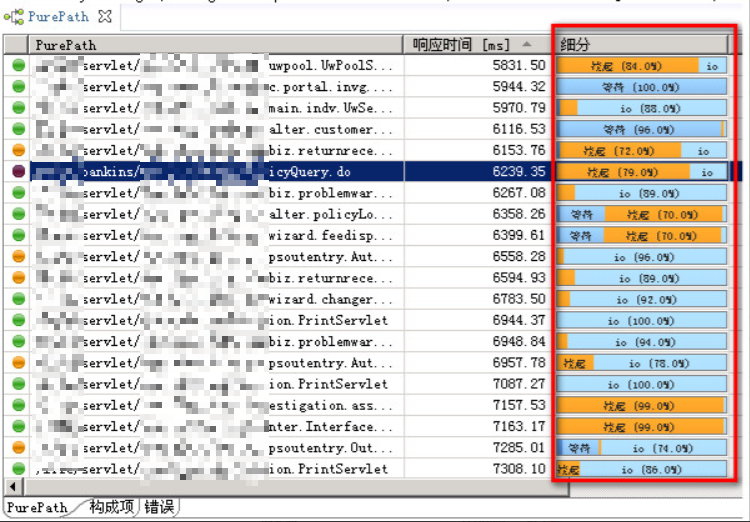
直接导致应用,具体到该系统前端用户的某一请求,由于 gc “stop the world” 导致响应时间大幅增加,原本 100 多 ms 就能完成的请求,直接由于 gc 导致的挂起多花了 7000ms!
这次我们使用 dynatrace 自带的 CPU 采样热点分析和内存快照分析工具来进行分析。
- 直接通过 dynatrace 对该台 jvm 做 heapdump 并直接在 dynatrace 上进行分析,分析结果如下:下图 1-4 的实例都是由 javamelody 这个 jar 包产生的。
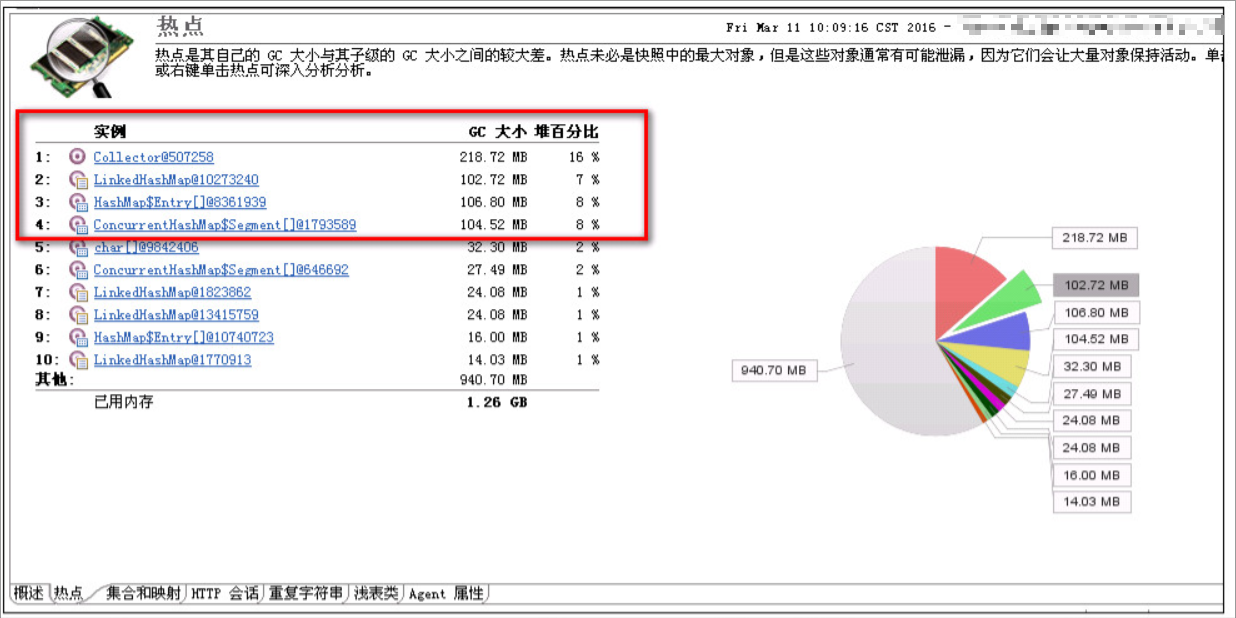
- 通过 cpu 采样分析,结果如下:直接看出是 javamelody 占用了较多 cpu
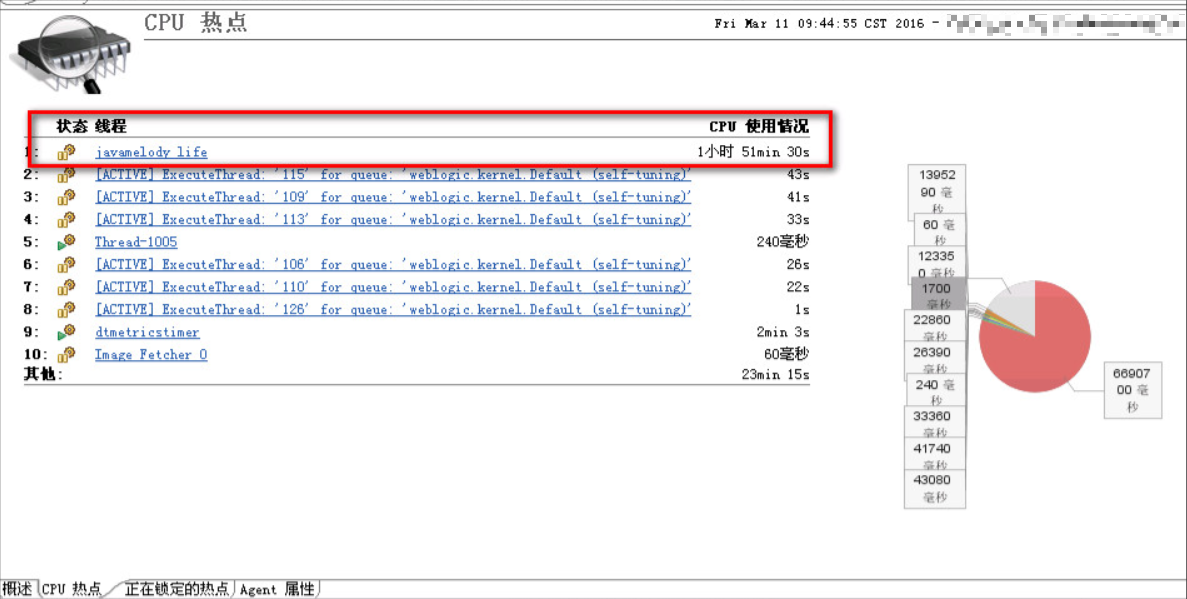
作为对比,其他 jvm 中根本没有加载 javamelody 这个包。
而联系项目组,得到的答复是:
javamelody-JVM监控程序。可以用来分析具体的问题点。该 jar 包会定时(较频繁)采集应用的相关指定的数据,并且对数据进行打包、压缩、发送。
而 javamelody 的这些操作是既消耗 CPU 又消耗 jvm 内存资源。对系统的行能造成了较大的影响。而在我们的建议下,项目组拿掉了这个 jar 包。改用 Dynatrace 的仪表板和报告.
总结
通过 dynatrace,我们发现了核心系统的问题,并快速的分析解决了该问题。解决问题之后,核心系统运行起来平稳而高效。从以前每天都要关注,出了问题抓耳挠腮,变成了今天的风淡云清。
系列文章
- 8 种 Java 内存溢出之一:Java Heap Space
- 案例 1: 某财险承保系统内存泄漏问题
- 8 种 Java - 内存溢出之二 - GC overhead limit exceeded
- 案例 2: 某寿险公司核心系统 GC 开销超限问题分析
- 8 种 Java - 内存溢出之三 - Permgen space
- 案例 3: 某财险公司运行时的 Perm 区内存溢出分析
- 8 种 Java - 内存溢出之四 - Metaspace
- 8 种 Java - 内存溢出之五 - Unable to create new native thread
- 8 种 Java - 内存溢出六 - Out of swap space?
- 8 种 Java 内存溢出之七 - Requested array size exceeds VM limit
- 8 种 Java 内存溢出之八 - Kill process or sacrifice child
