「译文」Kubernetes 时代的监控(二)
本文最后更新于:2025年2月22日 下午
这篇文章是关于库伯内特斯监测的系列文章的第二部分。第 1 部分讨论了 Kubernetes 如何改变你的监控策略,这篇文章分解了监控的关键指标,第 3 部分讨论了收集数据的不同方法,第 4 部分详细介绍了如何使用 Datadog 监控 Kubernetes 的性能。
如第 1 部分所述,使用 Kubernetes 进行容器编排需要重新考虑监控策略。但是,如果您使用适当的工具,知道要跟踪哪些指标,并且知道如何解释性能数据,那么您将对您的容器化基础架构及其编排有很好的可见性。本系列的这一部分将深入研究您应该监控的不同指标。
衡量标准从何而来
Heapster:库伯内特斯自己的指标收集器
ℹ️ 译者注:
当前 Heapster 已弃用,改为使用 prometheus 及 kube-states 和 node-exporter 获取。
如果不介绍 Heapster,我们就不能讨论 Kubernetes 度量标准:它是目前从您的 Kubernetes 集群获取基本资源利用度量标准和事件的首选源。在每个节点上,cAdvisor 收集有关 Heapster 运行的容器的数据,然后通过节点的 kubelet 进行查询。本系列的第 3 部分描述了收集 Kubernetes 度量的不同解决方案,将为您提供关于 Heapster 如何工作以及如何为此目的配置它的更多细节。
Heapster vs. 本地容器度量
很重要的一点是要理解你的容器引擎报告的度量 (Docker 或 rkt) 可以有不同于 Kubernetes 等效度量的值。如上所述,Kubernetes 依靠 Heapster 报告指标,而不是直接报告 cgroup 文件。Heapster 的一个局限性是,它收集 Kubernetes 指标的频率(又称 “时间间隔(housekeeping interval)”) 与 cAdvisor 不同,这使得 Heapster 报告的指标的整体度量收集频率难以评估。这可能会导致由于采样间隔不匹配而导致的不准确性,尤其是对于采样对于度量值至关重要的指标,如 CPU 时间计数。这就是为什么你真的应该考虑从你的容器而不是从 Kubernetes 跟踪指标的原因。在本文中,我们将强调您应该监控的指标。然而,即使你使用的是 Docker 指标,你仍然应该使用来自 Kubernetes 的 label 来聚合它们。
既然我们已经明确了这一点,那么让我们深入研究一下您应该监控的度量标准。
Key performance metrics to monitor 需要监控的关键性能指标
由于 Kubernetes 在您的基础设施中起着核心作用,因此必须对其进行密切监控。您需要确保 pod 是健康的,能够正确部署,并且资源利用率得到了优化。
Pod 部署
为了确保 Kubernetes 正确地完成工作,您希望能够检查 pod deployments 的健康状况。
在部署 rollout 期间,Kubernetes 首先确定运行应用程序所需的所需 pod 数量。然后它部署所需的 pod;新创建的 pod 已经启动并记为当前数量(current)。但是当前(current)的 pod 不一定能立即可用(available) 于预期用途。
1 | |
实际上,对于某些类型的部署,您可能需要在提供它们之前强制执行一个等待期。让我们假设在 Kubernetes 有一个 jenkins 集群,slaves 在集群中。他们需要一些时间来启动,所以你想让他们在启动期间不可用,不让他们处理任何传入的请求。你可以在你的 PodSpec 中使用 .spec.minReadySeconds,,它会暂时阻止你的 pod 变得可用 (available)。请注意,在某些情况下,准备就绪检查(readiness checks) 可能是一个更好的解决方案,以确保您的 pod 在收到请求之前是健康的(参见下面关于健康检查(health check)的一节)。
在 滚动更新 期间,您还可以在 PodSpec 中指定 .spec.strategy.rollingUpdate.maxUnavailable 可以确保在整个过程中至少有一定数量(或百分比)的 pod 可用。你也可以使用 .spec.strategy.rollingUpdate.maxSurge 指定可以在所需 pod 之外创建的额外 pod 的数量(或百分比)上限。
| 指标(Metrics) | kube-state-metrics 中的指标名称 | 描述 | 指标类型 |
|---|---|---|---|
| Desired pods | kube_deployment_spec_replicas | 部署开始时需要的吊舱数量 | 其他 |
| Available pods | kube_deployment_status_replicas_available | 现有 pod 数量 | 其他 |
| Unavailable pods | kube_deployment_status_replicas_unavailable | 现有但不可用的 pod 数目 | 其他 |
您应该确保可用(available) pod 的数量始终与预期部署过渡阶段之外的所需(desired) pod 数量相匹配。
运行中的 pod
| 指标 | 描述 | 指标类型 |
|---|---|---|
| 当前 pod 数 | 当前运行的 pod 数 | 资源:用量 |
密切关注当前运行的 pod 数量(例如,按节点或副本集)将为您提供动态基础设施演变的概述。
为了理解运行的 pod 数量如何影响集群中的资源使用 (CPU、内存等) ,您应该将这个度量与下一节描述的资源度量相关联。
资源用量
监控系统资源有助于确保您的集群和应用程序保持健康。
| 指标 | kube-state-metrics 指标 | 描述 | 指标类型 |
|---|---|---|---|
| CPU 使用率 | – | 目前正在使用的已分配 CPU 的百分比 | 资源:用量 |
| 节点 CPU 容量 | kube_node_status_capacity_cpu_cores | 集群节点的总 CPU 容量 | 资源:用量 |
| 内存使用 | – | 使用占总内存的百分比 | 资源:用量 |
| 节点内存容量 | kube_node_status_capacity_memory_bytes | 集群节点的总内存容量 | 资源:用量 |
| Requests | – | 容器运行所需的给定资源的最小量(应该在节点上求和) | 资源:用量 |
| Limits | – | 容器允许的给定资源的最大量(应该在节点上进行相加) | 资源:用量 |
| 文件系统的使用量 | – | 正在使用的磁盘容量(字节) | 资源:用量 |
| 磁盘 I/O | – | 从磁盘读取或写入磁盘的字节 | 资源:用量 |
CPU 和 memory
不用说,当性能问题出现时,CPU 和内存使用率很可能是您想要审查的第一个资源指标。
然而,正如本文第一部分所解释的那样,为了跟踪内存和 CPU 使用情况,你应该选择容器技术报告的指标,比如 Docker,而不是 Heapster 报告的 Kubernetes 统计数据。
为了访问节点的 CPU 和内存容量,kube-state-metrics (在第 3 部分中展示)公开了这两个指标:kube_node_status_capacity_cpu_cores 和 kube_node_status_capacity_memory_bytes。
kube-state-metrics 还报告了分别跟踪可用于调度的每个节点的 CPU 和内存资源的 kube_node_status_allocatable_cpu_cores 和 kube_node_status_allocatable_memory_bytes。请注意,这些度量并不跟踪实际预订,也不受当前调度操作的影响。它们等于节点容量中剩余的可用资源,还需要除去用于系统进程的资源量 (journald、 sshd、 kubelet、 kube-proxy 等等)
Requests vs. limits
对于 pod 调度,Kubernetes 允许你通过两种阈值指定每个容器可以消耗多少 CPU 和内存:
- Request 请求 represents 代表容器需要运行的最小 CPU 或内存量,这需要系统来保证
- Limit 限制 是容器允许使用的最大资源数量。默认情况下是无界的
小心陷阱
对于其他技术,您可能习惯于监控实际资源消耗,并将其与节点容量进行比较。对于 Kubernetes,如果一个节点上的容器 limits 的总和严格大于 requests 的总和(所需的最小资源) ,那么节点可能会被超额订阅(oversubscribed),容器可能会使用比实际需要更多的资源,这是很好的。例如,即使它们在一个节点上使用了 100% 的可用 CPU 资源,Kubernetes 仍然可以在节点上腾出空间来安排另一个 pod。只要所有容器都有足够的资源来满足它们的请求,Kubernetes 就会简单地降低现有 pod 可用的 CPU,以释放资源用于新 pod。这就是为什么监控节点上的请求总和并确保它永远不超过节点的容量比监控简单的 CPU 或内存使用情况要重要得多。如果您没有足够的容量来满足所有容器的最小资源需求,那么您应该扩展节点的容量,或者添加更多的节点来分配工作负载。
在很多情况下,节点上有一些超额订阅是好的,因为它可以帮助减少 Kubernetes 集群中的节点数量。您可以通过随时间监控请求 / 限制比率并跟踪它对容器资源使用的影响来优化它。
注意,因为版本 1.3 Kubernetes 为 Google Compute Engine 和 Google Container Engine 提供了自动缩放功能 (AWS 支持很快就会出现)。因此,在这些平台上,Kubernetes 现在可以根据 CPU 利用率调整部署、副本集或复制控制器中的数量(对其他自动伸缩触发器的支持是 alpha)。
ℹ️ 译者注:
现在 HPA(水平伸缩器)已经是可用的了。
容器资源度量
正如在 关于容器度量的章节 中所解释的那样,由于 Docker 报告的一些统计数据提供了更深入的(和更准确的)洞察力,因此也应该对它们进行监控。CPU 节流 (throttling) 指标就是一个很好的例子,因为它表示容器达到指定限制 (limit) 的次数。
磁盘使用和 I/O
使用中的磁盘百分比通常比磁盘使用量更有用,因为关注的阈值不取决于集群的大小。你应该绘制它随时间演变的图表,如果超过 80% 就触发警报。
从磁盘读取或写入磁盘的字节数的图形化为更高级别的度量提供了关键的上下文。例如,您可以快速检查延迟 (latency) 峰值是否由于 I/O 活动而增加。
网络
与普通主机一样,您应该监控来自您的 pod 和容器的网络指标。
| 指标 | 描述 | 指标类型 |
|---|---|---|
| Network in | 通过网络接收的每秒字节数 | 资源:用量 |
| Network out | 通过网络发送的每秒字节数 | 资源:用量 |
| Network errors | 每秒网络错误数 | 资源:错误 |
网络指标可以显示流量负载。如果您看到每秒网络错误数量不断增加那么您应该调查,这可能表明一个低级别的问题或网络错误配置。
容器健康检查
除了标准的资源指标,Kubernetes 还提供了可配置的健康检查。你可以通过 PodSpec 进行配置 checks 来检测:
- 当运行的应用程序进入 broken 状态(存活探测(liveness probe)失败)时,kubelet 将杀死容器
- 当应用程序暂时无法正确地处理请求时(就绪探测(readiness probe)失败) ,在这种情况下,Kubernetes 端点控制器将从与 pod 匹配的所有服务的端点删除 pod 的 IP 地址,这样就不会向受影响的容器发送任何流量
Kubelet 可以通过 HTTP 检查(最常见的选择)、 exec 检查或 TCP 检查对容器运行诊断活性和准备状态探测。Kubernetes 文档提供了 关于容器探测的更多细节,以及关于 何时应该使用它们 的提示。
使用 native 度量监控容器
正如我们所说的,容器度量通常应该优先于 Kubernetes 度量。容器可以理所当然地被视为迷你主机。就像虚拟机一样,它们代表驻留软件运行,驻留软件消耗 CPU、内存、 i/o 和网络资源。
如果您正在使用 Docker,请查看我们的 Docker 监控指南,其中讨论了 Docker 提供的所有可用的资源指标,您应该收集并监控这些指标。
在由 Kubernetes 标签提供的框架中使用 Docker 将使您了解容器的健康和性能。标签已经应用于 Docker 度量。例如,您可以通过 pod 跟踪正在运行的容器的数量,或者通过按 pod 名称划分的 RSS 非缓存内存 图来跟踪最需要 ram 的容器数量。
特定于应用程序的度量
为了正确地监控您的容器化基础设施,您应该收集 Kubernetes 数据以及 Docker 容器资源度量,并将它们与 运行在它们之上的不同应用程序 的健康状况和性能相关联。每张图片都有其特殊性,你应该跟踪和提醒的指标类型会因人而异。然而,吞吐量、延迟和错误 (throughput, latency, and errors) 通常是最重要的指标。
我们已经发布了监控指南来帮助您识别许多流行技术的关键指标,包括 NGINX, Redis, MongoDB, MySQL, Elasticsearch, 和 Varnish。
Heapster 的设计不是为了从运行在容器中的应用程序收集默认的度量标准。如果您想要更深层次的上下文,而不仅仅是系统度量,那么您必须为应用程序配备工具,以便从它们那里收集度量。
ℹ️ 译者注:
这些应用程序的监控指标可以通过 Prometheus 配合不同的 exporter 来实现监控。
与事件相关联
从 Docker 和 Kubernetes 收集事件可以让您了解 pod 的创建、摧毁、启动或停止如何影响基础设施的性能(反之也可以)。
当 Docker 事件跟踪容器生命周期时,Kubernetes 事件报告 pod 生命周期和部署。例如,跟踪 pod 故障可能表明配置错误或资源饱和。这就是为什么您应该将事件与资源度量关联起来,以便于调查。
Pod 调度事件
通过跟踪 Kubernetes 事件,您可以确保 pod 调度工作正常。如果调度屡次失败,您应该进行调查。集群中的资源(如 CPU 或内存)不足可能是导致调度问题的根本原因,在这种情况下,您应该考虑 向集群添加更多节点,或者删除未使用的 pod 以为 pending pods 腾出空间。
节点端口也可能是调度争用的原因之一。如果使用 NodePort 来分配特定的端口号,那么 Kubernetes 就不能将一个 pod 安排到已经使用该端口的节点上。这可能导致调度问题,原因是:
- 糟糕的配置,例如,如果两个冲突的 pod 试图声明同一个端口
- 资源饱和,例如,如果 NodePort 被设置但是 replica set 需要更多的 pods。在这种情况下,您应该扩展节点的数量或使用 Kubernetes service 服务 以保证它后面的多个 pods 可以存在于一个节点中
适当的告警
由于你的 pod 不断移动,他们报告的指标 (CPU,内存,i/o,网络。…) 必须跟随警报。这就是为什么它们应该使用在 pods 来来去去时保持稳定的东西来设置:自定义标签、服务名称、复制控制器或副本集的名称。
具体的用例
正如第 1 部分所讨论的,监控协调的、容器化的基础架构意味着从堆栈的每一层收集度量:从 Docker 和 Kubernetes,以及从主机和容器化的应用程序。让我们看看如何使用来自基础架构的所有组件的不同数据来研究性能问题。
假设我们在 Docker 容器中运行 NGINX,这是由 Kubernetes 精心编排的。
1. 显示性能问题的应用程序度量
当 NGINX 5xx 错误的数量突然暴涨到一个设定的阈值之后,我们会收到一个 警报。
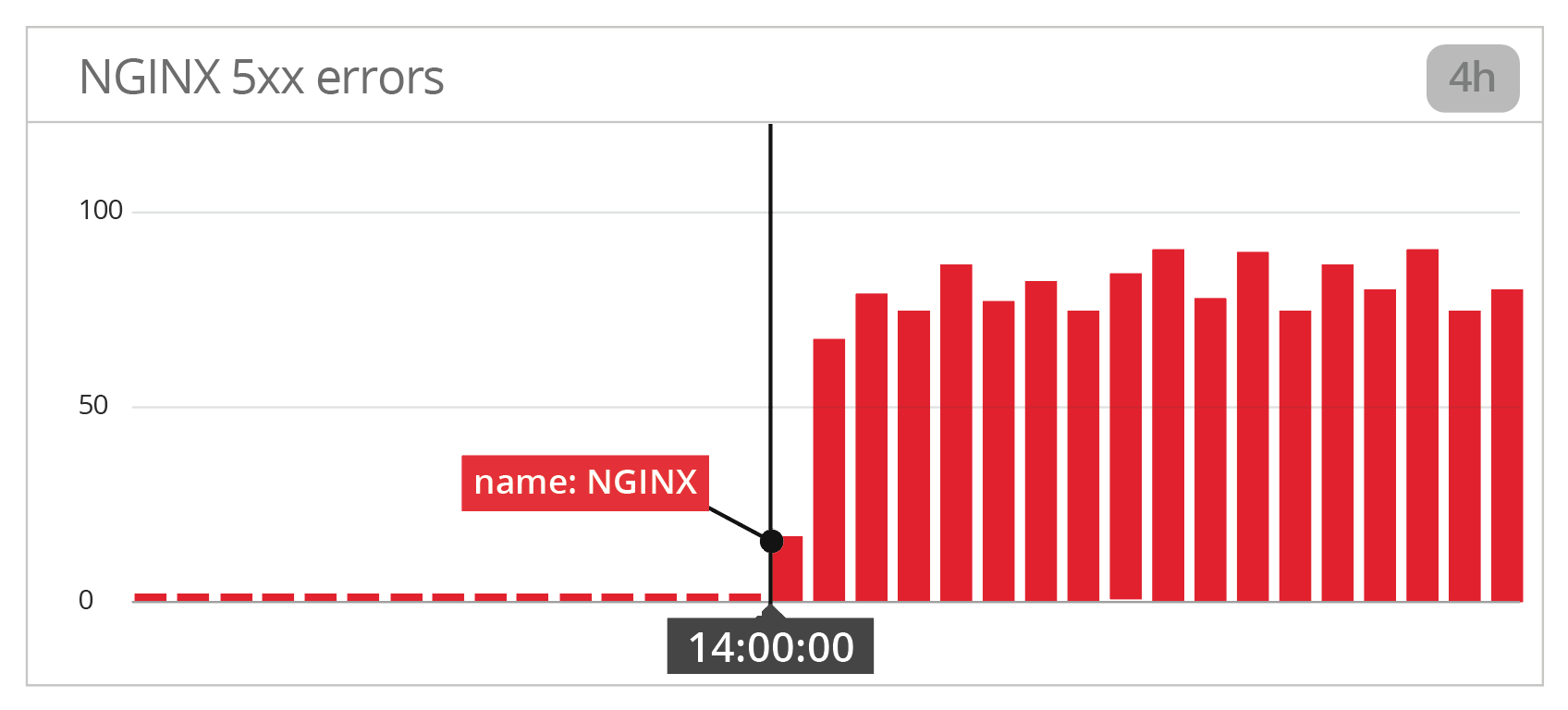
2. 相应的 Kubernetes 标签和事件
如果我们查看我们的 web 应用程序运行在哪些 pods 上,我们可以看到附加到它们的 Kubernetes 标签,它定义了所涉及的复制控制器,是 rc-nginx。当查看 Kubernetes 事件时,滚动更新部署 恰好发生在网络应用开始返回 5xx 错误的时刻。
让我们研究一下受此滚动更新影响的容器,以了解发生了什么。
3. 在容器层面上发生了什么
首先要考虑的通常是资源度量。记住,对于时间采样数据,Docker 指标应该优先于 Kubernetes。因此,让我们按照 Docker 容器绘制 CPU 利用率图,按 pod (或容器)分类,并进行过滤,以便只保留标签为 rc-nginx 的单元。
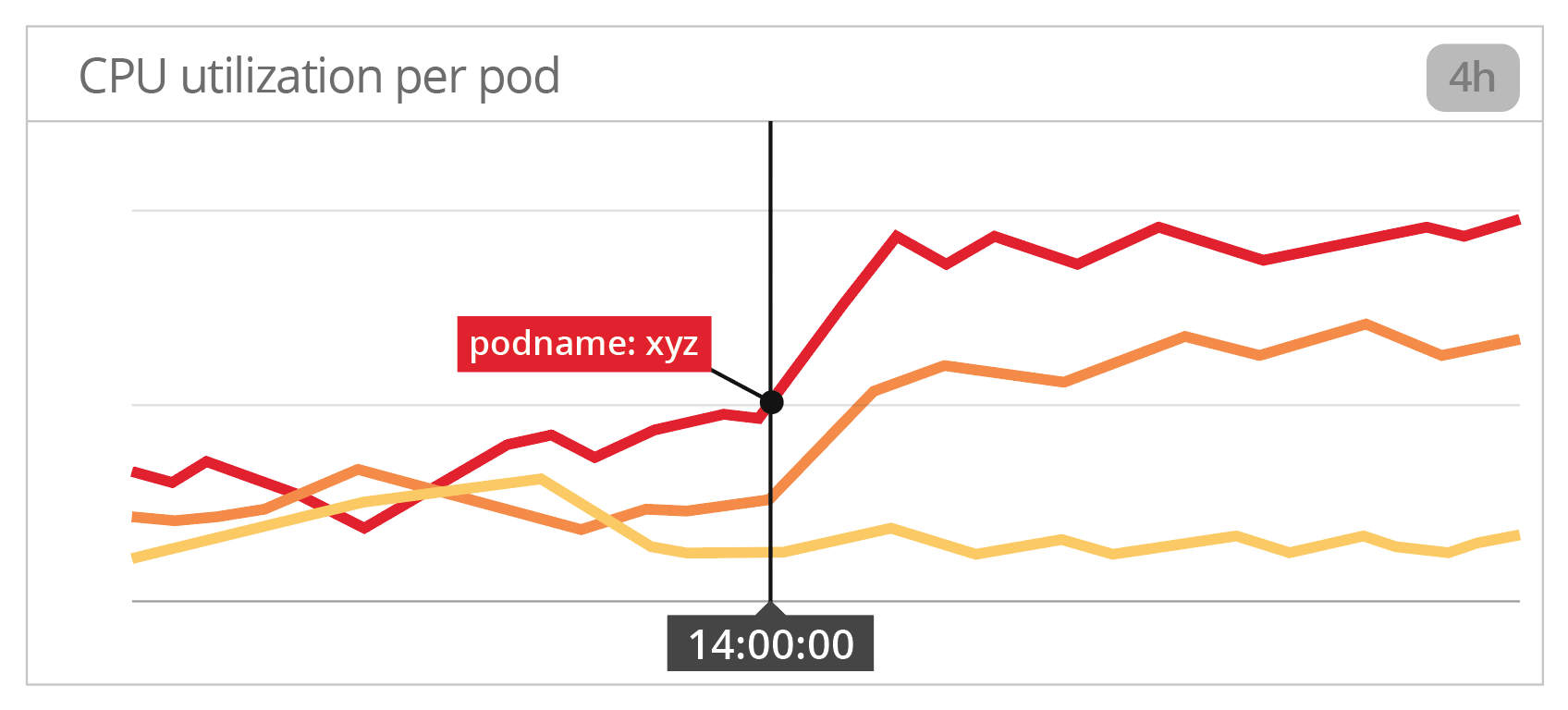
有意思!看起来某些 pods 的 CPU 使用量在 5xx 错误达到峰值的那一刻大幅增加。有没有可能运行这个 pod 副本的底层主机他们的 CPU 容量已经饱和了?
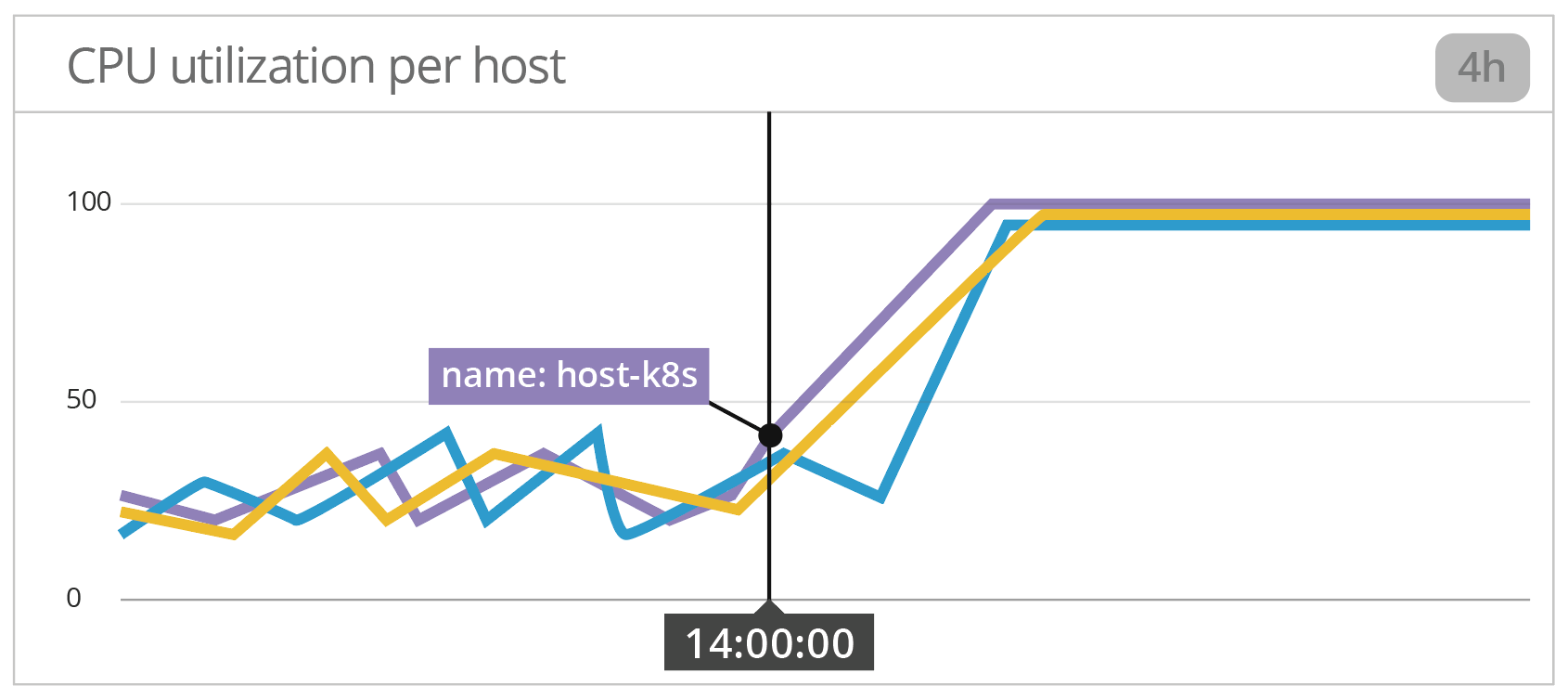
4. 确认假设的主机度量
通过绘制按主机分列的 CPU 使用情况图,我们可以看到确实有三台主机在那一刻将其 CPU 用到了最大值。
解决问题并进行事后检查
一个短期的解决方案是回滚到我们的 web 应用程序代码的更新,如果我们认为更新导致了这个问题。扩大主机的 CPU 容量也有助于支持更高的资源消耗。
如果合适的话,我们还可以利用 Kubernetes 的底层机制,该机制对单个 pod 可以使用的资源 (CPU 和内存)施加限制。在这种情况下,我们应该考虑降低给定 pod 的 CPU 限制。
在这里,我们结合了来自整个容器基础设施的数据来找出性能问题的根本原因:
- 报警的应用度量
- 标签,以确定受影响的 pod
- Kubernetes 事件寻找潜在的原因
- 由 Kubernetes 标签聚合的 Docker 度量用于调查假设的原因
- 确认资源约束的主机级度量
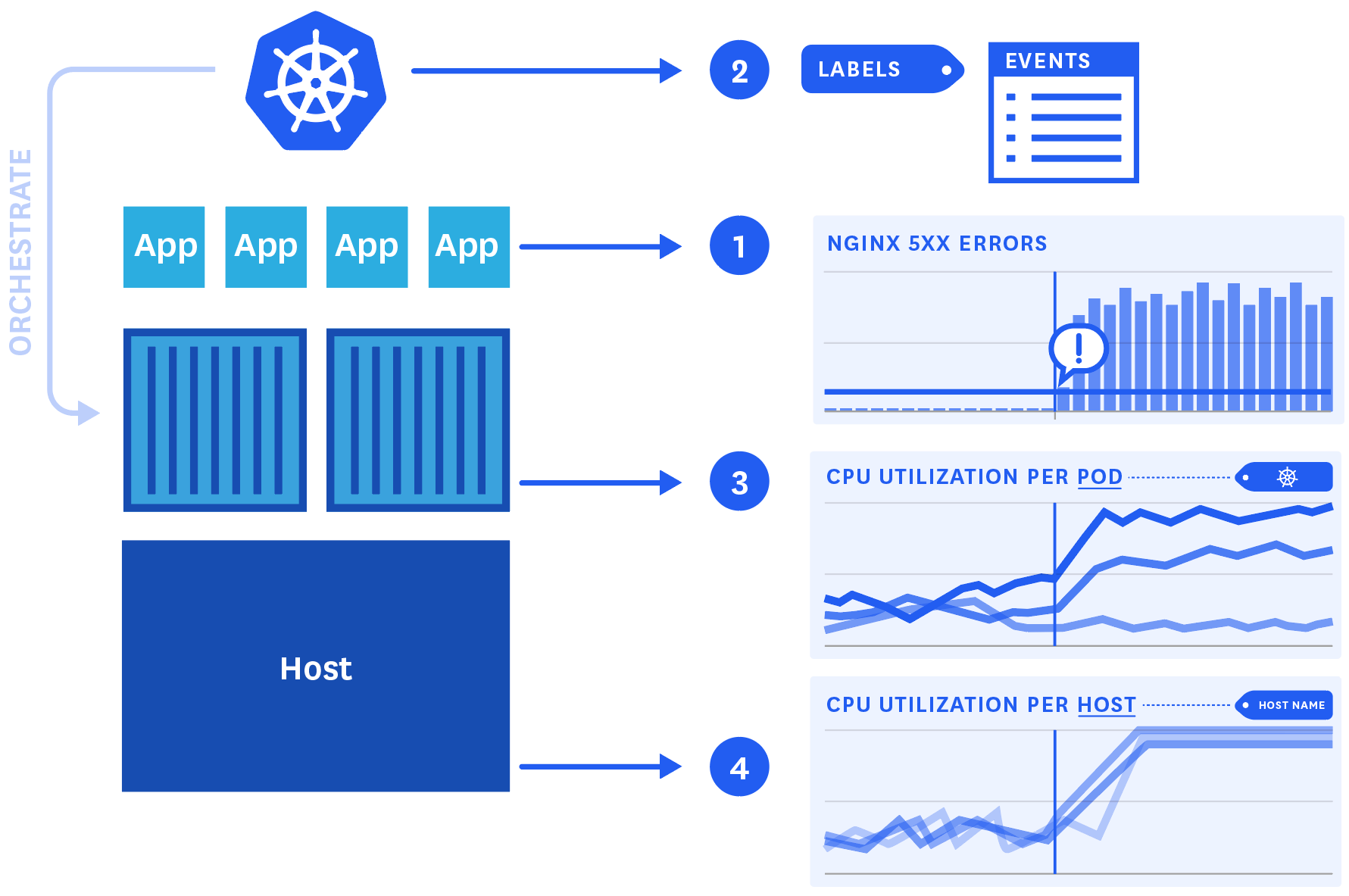
使用跨越您的容器化编排基础架构的数据来查找性能问题的根本原因
观察编排和调度
Kubernetes 使得处理容器变得更加容易。然而,这需要您彻底重新考虑如何监控您的基础设施。例如,有一个智能标签策略现在是必不可少的,因为可以聪明地结合来自 Kubernetes 的数据,你的容器技术,和你的应用程序的完全可观察性。
从 Kubernetes 收集资源指标的方法和工具与传统主机上使用的命令不同。本系列的第 3 部分介绍了如何收集您需要的性能指标,以便由 Kubernetes 适当地监控您的容器化基础架构及其编排。继续读下一章…
