「译文」Kubernetes 时代的监控(三)
本文最后更新于:2025年2月22日 下午
这篇文章是关于 Kubernetes 监测的系列文章的第 3 部分。第 1 部分讨论了 Kubernetes 如何改变你的监视策略,第 2 部分探讨了你应该监视的 Kubernetes 指标和事件,这篇文章涵盖了收集数据的不同方法,第 4 部分详细介绍了如何使用 Datadog 监视 Kubernetes 的性能。
第 2 部分深入研究应该跟踪的不同数据,以便能够正确监视由 Kubernetes 编排的容器基础架构。在这篇文章中,你将学习如何使用免费的开源工具手动设置度量收集、存储和可视化。
手工方案
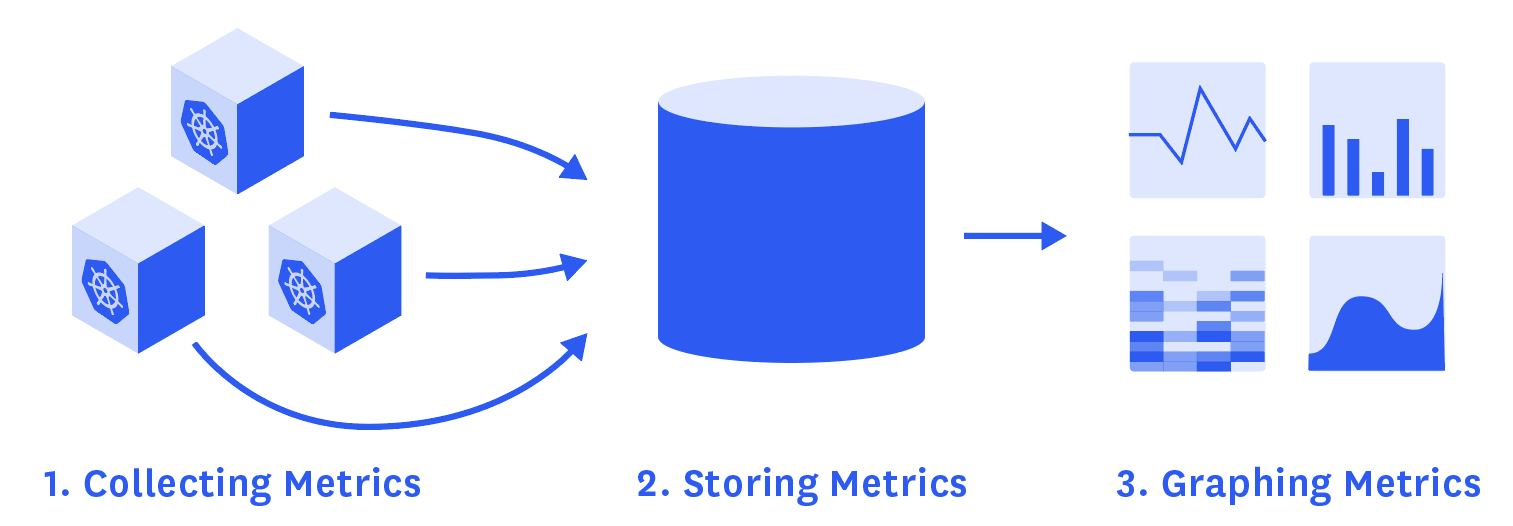
收集和存储来自 Heapster 的数据
Heapster 是如何收集 Kubernetes 指标的
正如第 2 部分中简要介绍的那样,现在 Heapster 是来自 Kubernetes 集群的基本资源利用度量标准和事件(由 Eventer 阅读和公开)的首选源代码。以下是它的工作原理。
在每个节点上,cAdvisor 收集有关 Heapster 运行的容器的数据,然后通过节点的 kubelet 进行查询。
cAdvisor 是一个集成到节点 kubelet 中的开源代理。它自动发现所有正在运行的容器,并收集它们的数据:CPU、内存、文件系统、网络。… … 它还收集有关自身和 Docker 守护进程的数据。Kubelet 导出这些数据并通过 API 重新公开它们。
和其他应用程序一样,Heapster 在 Kubernetes 上以 pod 的形式运行。它的 pod 在同一个集群中发现所有节点,然后从每个节点的 kubelet 中提取指标,按照 pod 和 label 聚合它们,并向监控服务或存储后端报告指标。
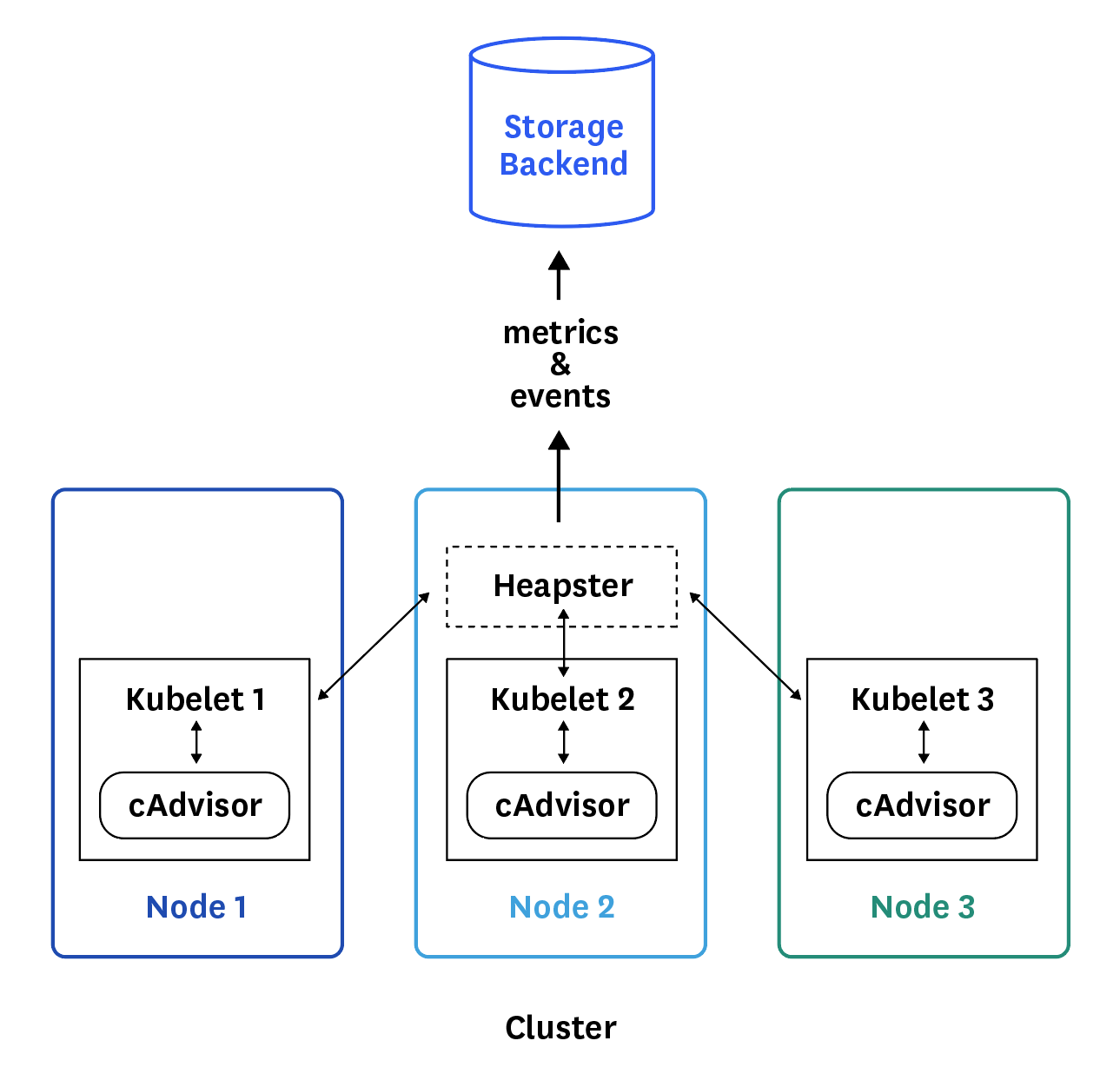
🔺Heapster 是如何工作的
配置 Heapster 度量的集合
即使 Heapster 被设计为能够从多个来源收集数据,目前支持的唯一来源是 Kubernetes (通过 cAdvisor)。这必须在带有 flag 的 /heapster 命令之后的 Heapster 部署规范中指定
--source=kubernetes:<KUBERNETES_MASTER>[?<KUBERNETES_OPTIONS>] (参见 下面 的部署示例).
选项是可选的 URL 查询参数,以 & 分隔,可用于为每个源设置自定义配置,而无需为每个源添加新的 Heapster flag。尽管 Kubernetes 是目前唯一启用的源类型,但是如果您希望从几个 Kubernetes 集群收集指标,那么您可以使用多个源。
您需要使用身份验证标记安全地将 Heapster 连接到 Kubernetes API 服务器,这里 详细介绍了配置步骤。
存储 Heapster 度量
您可以在不同的后端(也称为接收器 (sinks))之间进行选择,以存储 Heapster 公开的度量。必须在 /heapster 命令之后的 Heapster 部署规范中指定您选择的后端,并使用以下格式的标志 --sink=backendname:<CONFIG>[?<OPTIONS>] (参加 下面 的部署示例)。
与度量源一样,选项是可选的 URL 查询参数,由 & 分隔。这些参数允许您为每个接收器设置自定义配置选项。
设置为默认 使用 InfluxDB 作为存储后端,但是你可以在 这里 找到 Heapster 支持的所有当前接收器类型的列表,包括 Kafka 和 Elasticsearch,以及如何配置它们。
您可以同时将数据存储在多个接收器类型中。您需要为每个接收器类型使用单独的 --sink=... 标志,并附加该类型的所有接收器的选项。
部署 Heapster
要部署 Heapster,您需要根据要使用的后端创建本文 这里 描述的 Kubernetes 资源。
例如,对于 influxdb,这里是 Heapster 服务定义:
1 | |
下面是 Heapster 部署定义的一个例子:
1 | |
您的 sink 和图形工具将需要类似的服务和部署定义,因为它们运行在 pod 中。
添加 kube-state-metrics
kube-state-metrics 是一种提供 Heapster 没有提供的额外度量的服务。Heapster 公开关于组件(如 CPU、内存或网络)资源利用率的指标。另一方面,kube-state-metrics 监听 Kubernetes API 并生成关于 Kubernetes 逻辑对象状态的度量:节点状态、节点容量 (CPU 和内存)、每个部署所需 / 可用 / 不可用 / 更新的副本数量、 pod 状态(例如等待、运行、就绪) ,等等。
Here are all the metrics available from kube-state-metrics, which works only with Kubernetes version 1.2 or later.
这里 是来自 kube-state-metrics 的所有可用指标,它们仅适用于 Kubernetes 版本 1.2 或更高版本。
需要注意的是,它的工作方式与 Heapster 不同,后者只是一个重新格式化和公开已经由 Kubernetes 生成的指标的中介,而 kube-state-metrics 本身生成指标。
从 kube-state-metrics 收集度量
可以从 kube-state-metrics API 以明文或 protobuf 格式收集 kube-state-metrics 度量。它们可以被能够分析这些数据的监控工具吸收。工具还可以与 Prometheus Go 客户端 及其 HTTP 端点集成。
可以像只有一个副本的经典 Kubernetes 服务那样部署 kube-state-metrics。
您可以通过从 kube-state-metrics 根文件夹 运行 Make container 来构建容器镜像。
然后,您可以构建并运行它在一个只读访问您的 Kubernetes 集群的 pod 中。要创建必要的 Kubernetes 服务和部署,请运行 kubectl apply -f kubernetes
以下是创建的服务:
1 | |
需要注意的是, prometheus.io/scrape: 'true' 这一行允许 Prometheus 或其他解析工具在部署完成后立即收集 kube-state-metrics 指标。
通过命令行进行抽查
一些特定于 Kubernetes 的指标可以通过命令行进行抽样检查。最有用的一个是 kubectl get,它允许显示不同的 Kubernetes 对象的状态。例如,为了监视你的 pods 部署,你可以看到 可用的、需要的和正在运行 的 pods 数量:
1 | |
命令行工具非常适合进行抽查,但您通常希望能够跟踪这些指标随时间的演变。幸运的是,有些监视工具使您能够轻松地将这些数据可视化,并将其与资源利用率等其他指标相关联。
图形化 Kubernetes 度量
一旦您手动配置了度量收集和存储,您就可以连接一个仪表板接口,比如 Grafana (通常与 InfluxDB for Heapster 度量结合使用) ,它将获取并绘制监控数据。
当使用 Heapster 度量时,你的存储后端和数据可视化应用程序都需要运行在可以公开自己为 Kubernetes 服务的 pods 中;否则 Heapster 将无法发现它们。
收集容器和应用程序度量
正如第 1 部分和第 2 部分所讨论的,正确地监控您的协调的、容器化的基础设施需要您结合来自 Kubernetes 的度量、事件和标签、您的容器技术、在您的容器中运行的应用程序,甚至底层主机。
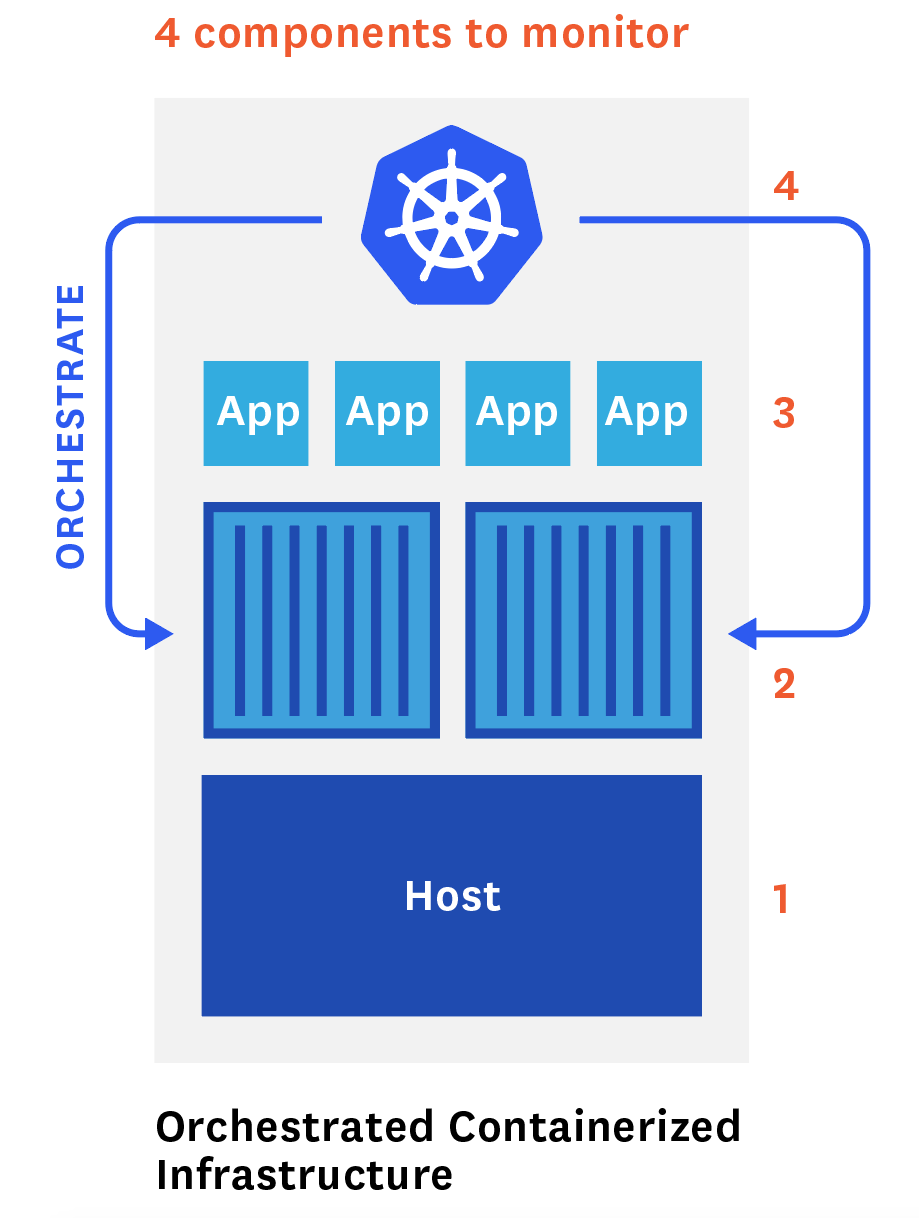
这就是为什么您的可视化或监视工具需要提供强大的关联特性,以及从所有这些组件收集度量的能力。下面我们将概述如何使用本地工具和开源工具来实现这一点。
来自您的容器技术的度量
如果您已经阅读了本系列的第 2 部分,那么您就会知道,为了避开 Heapster 为 Kubernetes 度量所使用的不确定的收集间隔,您应该支持从您的容器技术中本机收集的资源度量统计数据,比如 CPU 使用率。注意,Kubernetes 将标签应用于 Docker 度量。
如果您正在使用 Docker,您将在我们的 Docker 监控指南 中找到关于可以用于收集所有 Docker 度量的不同机制的详细信息。
使用 Kubernetes 自定义度量收集应用程序度量
仅仅依靠 cAdvisor 和 Heapster 从您的容器化应用程序中收集度量标准是非常有限的。Kubernetes 1.2 之后,一个新特性(仍处于 alpha 阶段)确实允许 cAdvisor 从运行在容器中的应用程序中 收集自定义度量,但前提是这些度量必须以 Prometheus 格式 本地公开,这种情况目前只适用于 少数应用程序。
有些工具允许您绕过 cAdvisor-Heapster 组合,直接使用 Prometheus 来收集和存储指标。条件是这些指标必须以普罗米修斯格式公开。
跨云集群监测
由于 Kubernetes 版本 1.3,您现在可以在不同的云提供商之间分发您的 Kubernetes 集群。请注意,这可能会使您的监控复杂化,因为尽管像 InfluxDB 这样的存储后端允许您存储来自多个云的指标,但是 Heapster 目前没有提供任何聚合这些数据的方法。
使用 Datadog 进行生产监控
本文的第一部分概述了如何使用内置和开源工具手动访问关于您的容器化基础设施的性能数据。对于生产基础设施,您可能需要一个更全面的监控系统:
- 无缝集成到 Kubernetes、 Docker 和所有容器化应用程序,因此您可以在一个地方看到所有的度量和事件
- 提供服务发现,以便您可以无缝地监视移动的应用程序
- 可以快速设置和配置
- 提供先进的监控功能,包括强大的警报,异常值 及 异常 检测,使用 label 和 tag 的动态聚合,以及系统之间度量和事件的相关性
在 Datadog,我们一直在努力解决 Kubernetes 给监控带来的新挑战,第 1 部分详细介绍了这些挑战,包括 服务发现。Datadog 自动收集来自 Kubernetes 和 Docker 的标签和标签,并与所有需要监控的组件集成。Datadog 聚合了您需要的所有指标,包括第 2 部分中提到的指标,即使您的集群分布在多个数据中心或云提供者之间。
本系列的下一部分和最后一部分将介绍如何使用 Datadog 监视由 kubernetes 编排的基础架构,并向您展示如何在自己的环境中设置所需的集成。
